


一、系统资源
通常服务器的性能会卡在四个地方:CPU、内存、网络IO和磁盘IO。
二、性能调优
2.1 CPU
一个好的架构,服务器的CPU总消耗总是平均的分布在各个cpu上,CPU的消耗在70%左右。
1)使用多线程 或多进程编程,充分利用多核CPU。老的线程库效率太低,需要升级用NPTL 。
2)进(线)程数不要远超cpu数,减少进程无味的切换。
3)慎重选择阻塞性IO,阻塞会导致进程切换,浪费CPU资源。
4)事件发生的时间无法估计或比较长,则不应该使用轮询的方式,尽量用异步方式等待事件就绪。
5)谨慎用锁,尽量把数据分配到各个线程,减少共享资源,减少竞争,lockfree。
6)类中有联系的数据尽量放在相邻的位置,可以放到一个cacheline里。
7)慎用字符串操作,比如sprintf,snprintf,因为%d %s等等都需要CPU资源去做词法分析,数量多的话,也是不菲的开销减少系统调用,例如time,主要消耗在用户态和内核态之间的切换。
8)优化算法,减少遍历操作。
9)优化架构,把系统管道调整到统一的半径,解决瓶颈。
10)使用一些静态池技术,比如内存池,线程池,连接池等,用空间换时间。
一个好的架构,服务器的CPU总消耗总是平均的分布在各个cpu上,CPU的消耗在70%左右。
2.2 内存
程序需要多少内存需要在设计的时候估计清楚,如果占用的内存接近物理内存,将会使用交换分区,影响性能。
2.3 网络IO1)使用epoll代替select
2)使用非阻塞的模式来开发
3)减少消息交互次数
4)数据流使用长链接
5)优化应用层协议
6) 使用DPDK
2.4 磁盘IO
1)内存中缓存写入磁盘的数据,批量写磁盘,减少写入次数
2)利用顺序写,减少寻道次数
3)内存缓存热点数据,缓解磁盘读压力
4)对磁盘IO密集型的服务使用SSD盘
三、常用工具
3.1 top(CPU&内存)
可以查看系统中运行的进程的状况,CPU使用状况,系统负载,内存使用等。它是检查系统进程运行状况最方便的工具了,它默认显示部分活动的进程,并且按照进程使用CPU的多少排序。它可以显示全部CPU的使用状况,也可以显示每个进程都运行在那个CPU上面。
主要可以用top来看哪些进程或者哪类进程占用CPU和内存资源最多,以此迅速定位存在性能问题的进程,以及运行异常的进程。
load average: 0.06, 0.60, 0.48 - 系统负载,即任务队列的平均长度。 三个数值分别为 1分钟、5分钟、15分钟前到现在的平均值。这个值最好小于0.7,一般大于0.7说明需要调优。
%CPU这个字段在多线程多核的环境中会超过100。
3.2 free(内存)
free命令显示系统内存的使用状况(物理内存和交换内存)通过这个命令我们可以看到系统进程实际使用的物理内存,buffer和cache使用的物理内存。
第二行的used/free是OS角度,包括buffer和cache使用的内存。
第三行的used/free是用户角度,不包括buffer和cache使用的内存。
3.3 vmstat(综合)
vmstat是一个很全面的性能分析工具,可以观察到系统的进程状态、内存使用、虚拟内存使用、磁盘的IO、中断、上下问切换、CPU使用等。

Procs
r:运行的和等待(CPU时间片)运行的进程数,这个值也可以判断是否需要增加CPU(长期大于1)b:处于不可中断状态的进程数,常见的情况是由IO引起的Memory 类似free命令
Swap
si: 交换内存使用,由磁盘调入内存so: 交换内存使用,由内存调入磁盘内存够用的时候,这2个值都是0,如果这2个值长期大于0时,系统性能会受到影响。磁盘IO和CPU资源都会被消耗。
IO
bi: 从块设备读入的数据总量(读磁盘) (KB/s),bo: 写入到块设备的数据总理(写磁盘) (KB/s)随机磁盘读写的时候,这2个 值越大,能看到CPU在IO等待的值也会越大System
in: 每秒产生的中断次数cs: 每秒产生的上下文切换次数上面这2个值越大,会看到由内核消耗的CPU时间会越多CPU
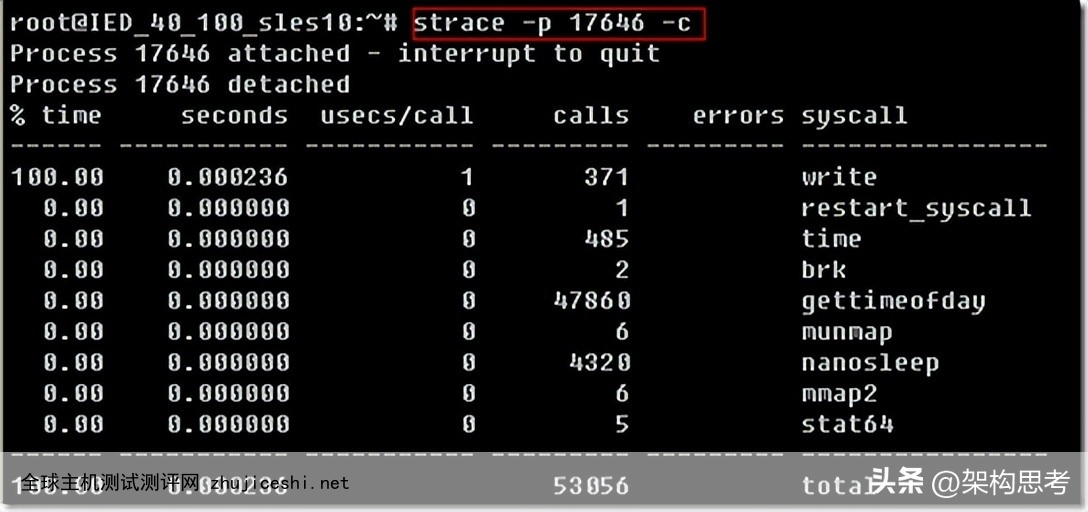
us: 用户进程消耗的CPU时间百分比us 的值比较高时,说明用户进程消耗的CPU时间多sy: 内核进程消耗的CPU时间百分比sy 的值高时,说明系统内核消耗的CPU资源多,这并不是良性的表现,我们应该检查原因。wa: IO等待消耗的CPU时间百分比wa 的值高时,说明IO等待比较严重,这可能是由于磁盘大量作随机访问造成,也有可能是磁盘的带宽出现瓶颈(块操作)。id: CPU处在空闲状态时间百分比3.4 Strace(CPU)
可以用来查看一个进程在执行过程中的系统调用和所接收的信号。
3.5 tcpdump(网络)
linux下的抓包工具。可以把抓下来的信息重定向到文件里。然后在windows下用ethereal来分析。很强大
3.6 gprof(CPU)
程序中每个函数的CPU使用时间。每个函数的调用次数。并提供简单调用关系图。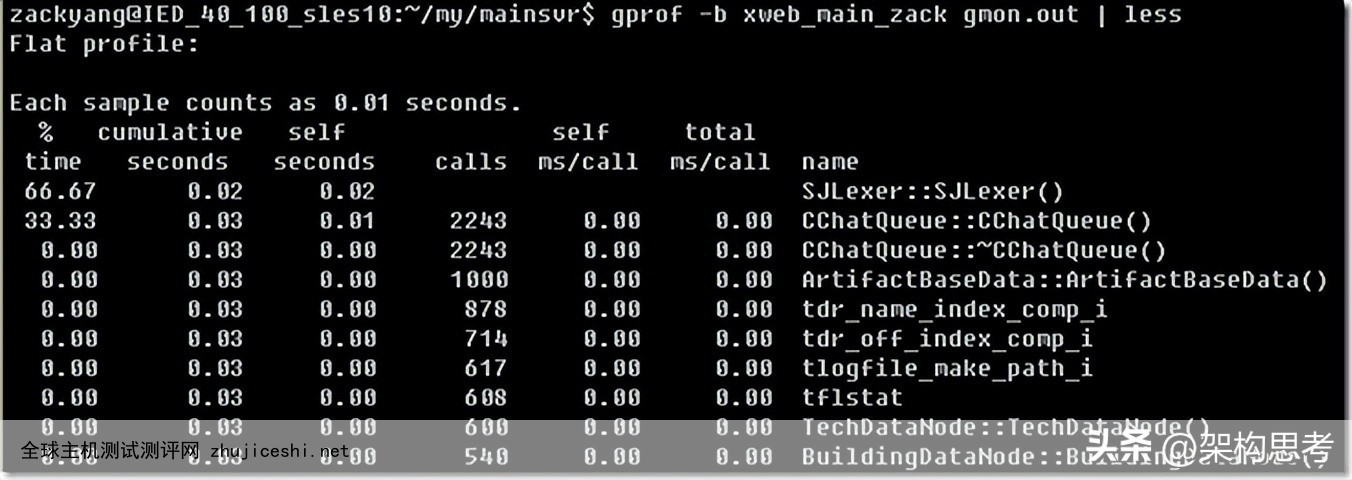
使用步骤:
用gcc或g++编译程序时,使用-pg参数执行编译得到的运行程序,会产生一个gmon.out文件使用gprof命令。查看结果信息。(gprof -b proc_name gmon.out | less)3.7 dstat (综合)
dstat 是一个可以取代vmstat,iostat,netstat和ifstat这些命令的多功能产品。dstat克服了这些命令的局限并增加了一些另外的功能,增加了监控项,也变得更灵活了。dstat可以很方便监控系统运行状况并用于基准测试和排除故障。
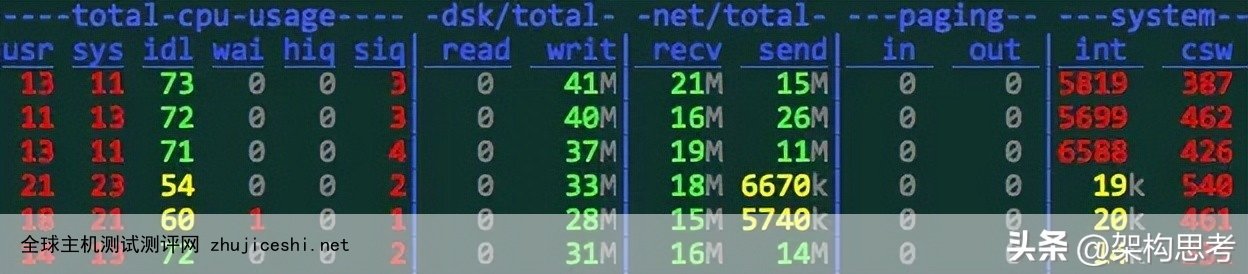
3.8 mpstat (CPU)
它能实时监测多处理器上每个CPU的使用情况。
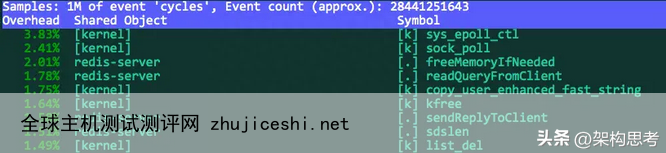
3.9 perf (CPU)
perf top命令可以查看哪些内核调用或用户调用的性能。另外perf stat通过概括精简的方式提供被调试程序运行的整体情况和汇总数据。
3.10 lsof (文件)
它能列出当前系统打开的文件描述符,可以看到哪些进程打开了哪些文件。文件描述符有两个层次的概念:用户级限制和系统限制,用户级限制可以通过ulimit
-n查看,系统级限制可以通过sysctl
-a命令查看,其中fs.file-max是整个系统共能打开的文件描述符,epoll.max_user_watches是一个用户能往epoll内核事件表中注册的事件总量,往epoll内核事件表中注册一个事件,在32位系统上大概消耗90字节的内核空间,在64位系统上则消耗160字节的内核空间。
3.11 netstat (网络)
可以打印本地网卡接口上的全部连接,路由表信息,网卡接口信息等,一般用netstat -apn
3.12 ifstat (网络)
它是一个网络流量监测工具,可以输出各个网卡的in/out流量信息。
3.13 iostat (磁盘)
它主要用于监控系统设备的IO负载情况。
3.14 nc (调试工具)
主要用来快速构建网络连接。可以让它以服务器方式运行,监听某个端口并接收客户连接,可以用于调测客户端程序。也可以使之以客户端方式运行,向服务器发起连接并收发数据,可以用于调试服务器程序。
文章来源:
https://www.jianshu.com/p/316b17acde6a
0 留言