



原标题:在知乎,看见ChatGPT变革的第一束光
机器之心报道
作者:微胖
有变革,知乎必有回响。搜索「ChatGPT」,仿佛瞬息挪移到能听见号角的最前线:
创新工场董事长李开复总结后 ChatGPT 时代拯救自己职业的通用法则;
DeepLearning.AI 创始人吴恩达警醒人们,将伦理与法律追问置于狂热之前;
一流科技创始人袁进辉觉得一个迫在眉睫的需要研究的问题是,怎么区分由人类生成的文本和 ChatGPT 生成的文本?
《数字化生存》作者、北大新闻传播学院胡泳则在「知聊八点半」圆桌直播中提出,人工智能的发展方向并不一定要「类人」,而应该是提升人的能力;
…...
透过问答、话题、圆桌、想法、热点直播,行业大佬接连现身中文互联网的高质量问答社区;投资人、科研人员、创业者和从业者彼此联结,一同探索 ChatGPT 前沿的一切面向,并思考他们的发现对未来的影响。
短短四个月,知乎「ChatGPT」话题热度已经打破 2015 年以来「AlphaGo」话题创下的纪录,当前讨论累计 22 万,总浏览量高达 3.8 亿。
 话题热度爆表,呈现方式也是全方位、多维度。
话题热度爆表,呈现方式也是全方位、多维度。
一、首发的力量
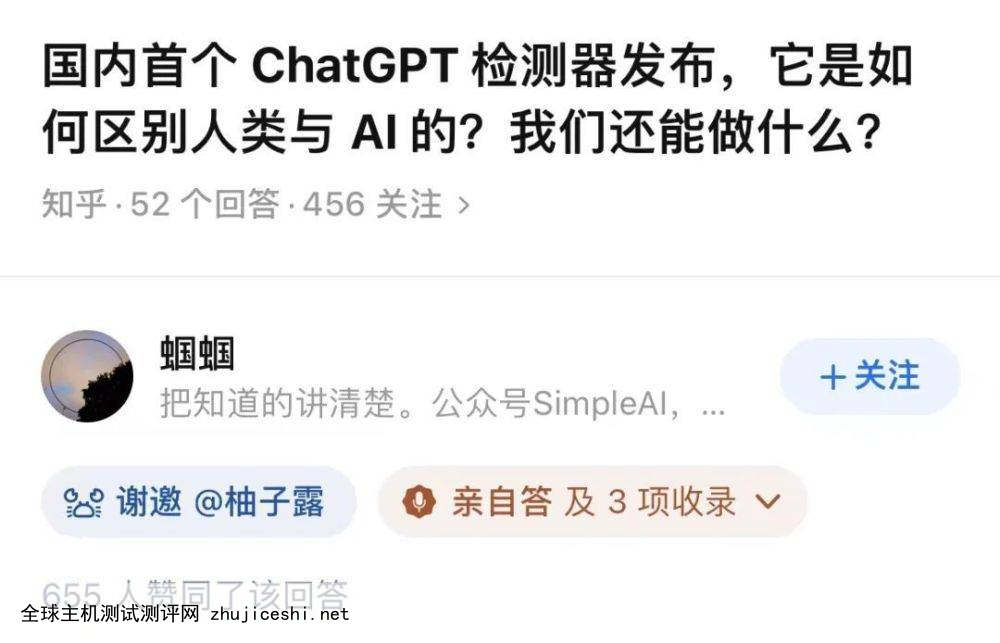
2023年1月2日,一位普林斯顿大学计算机科学专业的学生发布了GPTZero,这个程序可以「快速有效地」破译一篇文章的作者是人类还是 ChatGPT。
看到消息后,知乎答主「蝈蝈」有种被偷袭的感觉。ChatGPT 推出后的第 10 天,「蝈蝈」郭必扬,一位上海财经大学信息管理与工程学院 AI Lab 三年级博士生已经和朋友们着手这项工作,「我们其实是最早开始做 ChatGPT 检测器的团队。」他说。
GPTZero 发布一周内就有超过三万人试用,应用程序一度崩溃。郭必扬紧张起来。原计划除了检测器,这支八人团队还要做人工测评和语言学的统计分析。显然,眼下不能再等了。
用现有数据集训练了几个检测器后,1月11日,他们在知乎放出 demo ,这是国内第一个 ChatGPT 检测器。当时临近春节,本应陪家人聊天叙旧的郭必扬一直盯着屏幕,谁都不理。「家人觉得,我们可能是在做什么大事情。」
处在一个技术迭代越来越快的行业,最可怕的不是技术被外泄,而是没有足够多的人了解你的技术和你,更何况与 ChatGPT 革命性突破有关?
郭必扬和伙伴分秒必争推出 demo 的时候,一连串与 ChatGPT 相关的工作也陆续出现在知乎。
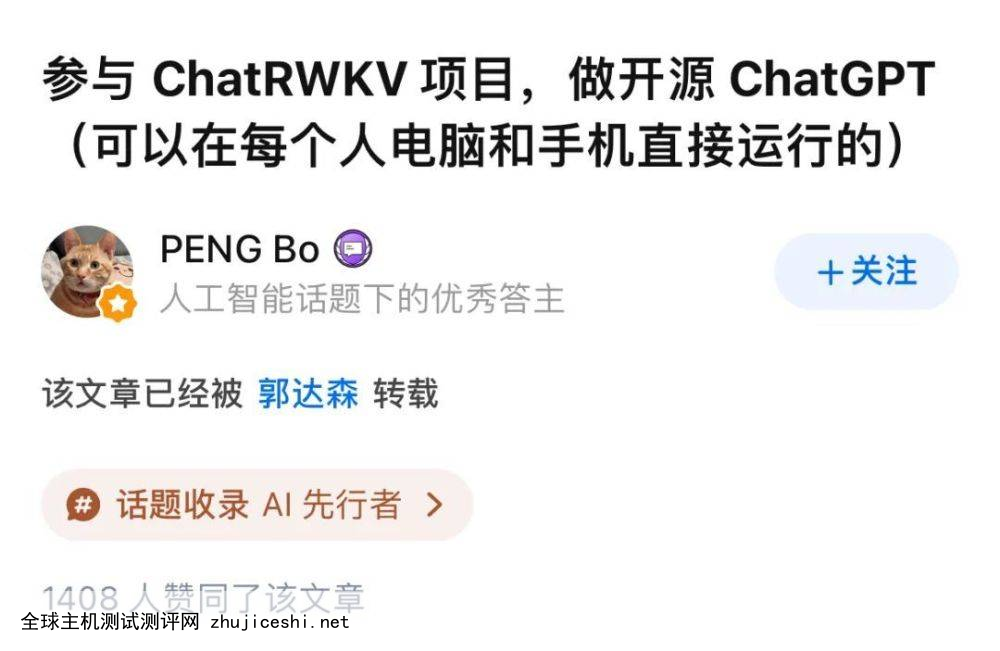
人工智能话题优秀答主 PENG Bo,一个公开对标 ChatGPT 的开源项目 ChatRWKV 作者在知乎呼吁更多人参与共建生态。
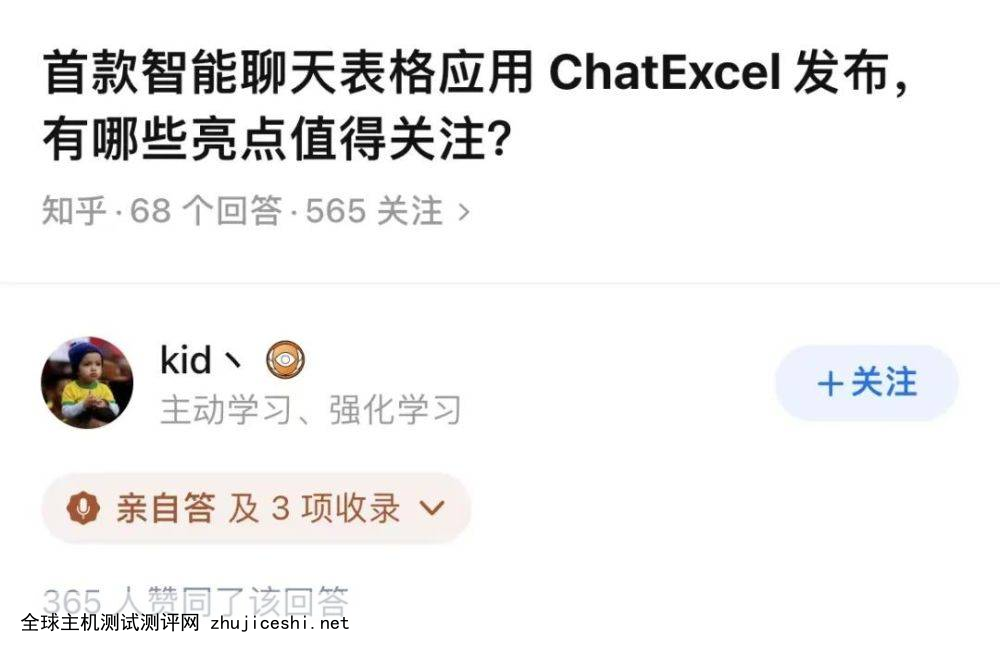
2 月底,第一款用自然语言指挥 Excel 工作的作品 ChatExcel 在知乎独家首发。
不过,接踵而来的社区反馈让郭必扬有些意外。
发布之前,他们比较过两个检测器,因为接受过数据集训练,他们检测器的实际效果比 GPTZero 好很多。一流科技创始人袁进辉也在知乎上谈到怎么区分由人类生成的文本和 ChatGPT 生成的文本,「是一个迫在眉睫的问题。」
最初,认为这项工作没有意义的观点接连不断。
「我们关注的是检测假消息,而不是ChatGPT 生成的假消息。如果说一个分类器只能处理由 ChatGPT 生成的假消息,那我换一个生成器不就完了?」
也有人认为「我们可以通过润色避免被检测为 ChatGPT。」
郭必扬决定亲自回应。「可以说我们检测器效果不好,但说检测器没意义,那我可有意见了。法律有漏网之鱼,不法之徒可以钻法律的空子,这说明法律没有意义吗?」
当人们为了避免被检测出来而对 ChatGPT 内容润色、修改时,检测器的作用已经达到。有一万种方法绕过各种监管,我们能做的只能是增加「不负责任的成本」。
随着时间的推移,支持和鼓励的声音多了起来。
「检测器的价值见仁见智,但个人觉得这个数据集是比较有价值的,可以来做一些有意思的事情。」 有人说。
中国信通院云大所内容科技部研究员呼娜英在知乎「知聊八点半」圆桌直播中表示,反作弊技术目前确实没有 ChatGPT 技术强大,必然会出现「猫鼠游戏」的现象,「但终究魔高一尺道高一丈。」
其实,决定上知乎发表作品等于选择进入一个复杂性系统。所谓复杂性,是指它不是线性的,不会按照你的预期运作,有很多维度和变量,难以预测,也因此会有一些「猝不及防」,但也有收益甚至意外惊喜。
现在,郭必扬团队的检测器在 Github 上已有6、700颗星。数据集和模型可能被下载上万次,不到两个月文章就有了 20 个引用。「这些是我们之前想不到的。」他有些感慨,「(文章被引增速)比我之前任何一篇文章都要快。」
知乎独家首发后没多久,WPS 就联系上 ChatExcel 背后的团队。开源项目 ChatRWKV 也得到了头部科技媒体的报导。
除了难以预测,知乎系统的复杂性还包括一种自适应性,发布一个作品会改变这个系统,系统也会反过来校准你的产品或者研究。
2022 年 11 月,谢凌曦所在团队将一份重要论文放到 arXiv 预印本网站后,也立刻发布在了知乎,标题显示某气象大模型,「中长期气象预报精度首次超过传统数值方法。」
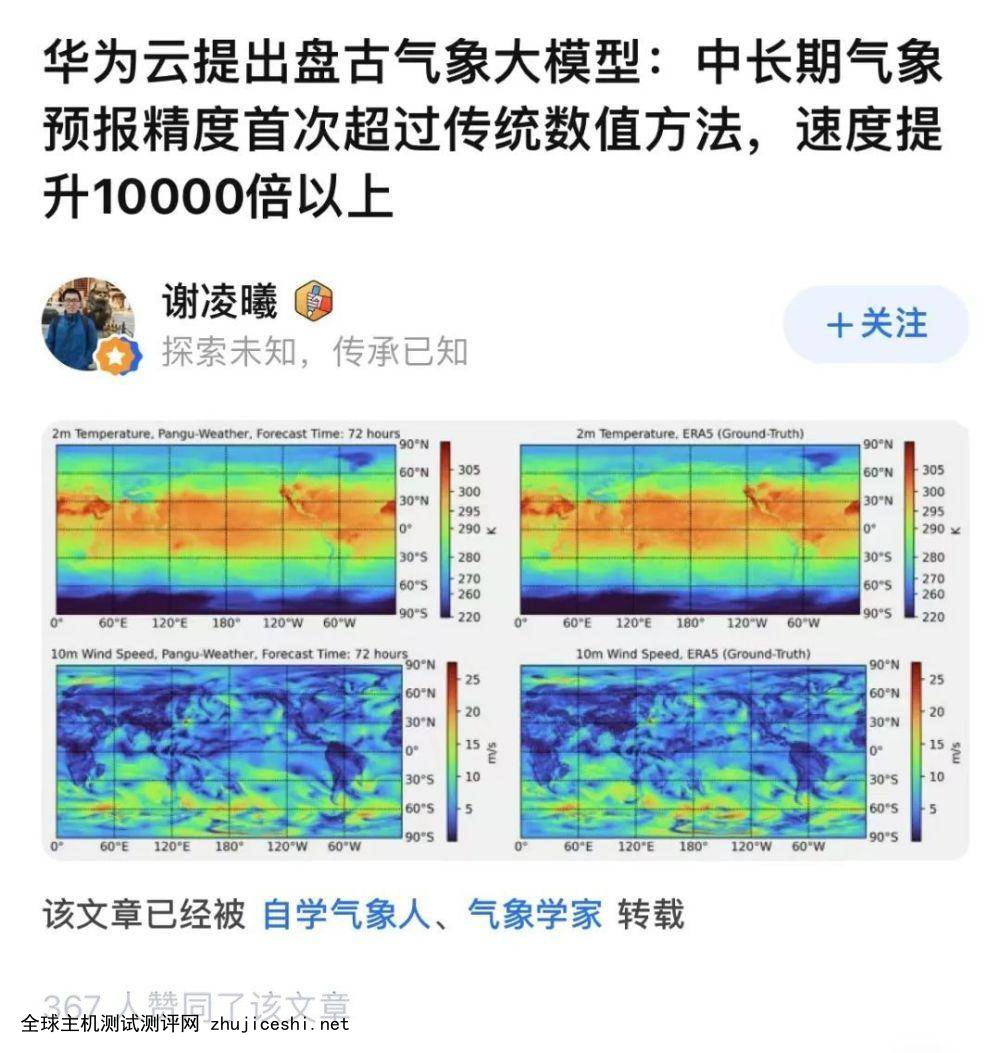
「标题让我火速去拜读了原文。」一位网友读完后,即对文章取得的成绩表示赞赏。在评论区与团队成员一番切磋讨论后,她分享了自己看法:
「AI 模式的输入是来自 ERA5(观测和模式同化出来的分析场),所以也是利用了模式预报,模式不预报就没有这个 ERA5(也就是 AI 的输入),所以模式还是得跑,并没有独立替代模式预报。目前是(传统模式同化+AI 预报)>(传统模式同化+传统模式预报)」。
AI 大模型是在 ERA5 数据上做的训练。ERA5 数据是再分析数据,主要是通过对各种来源(地面、船舶、无线电探空、测风气球、飞机、卫星等)的观测资料进行质量控制和同化处理,而获得的一套完整的再分析资料集。
这里的同化处理,就是把一些观测数据变成标准的网格化气象数据。在没有覆盖这些技术的情况下,不应该声称超越了传统的数值天气预报方法(NWP)。
「是的,这个应该还要不少时间,第一个问题就是数据似乎很难获得(所以国内外相关工作很少)。」团队成员也认可。
其实,「AI 还没法做,或者说,AI 还没有正式能做这一步,主要原因是没有数据。」谢凌曦后来对我们解释道。要做的话,AI 的输入端就要拿到诸如卫星、气象站这些数据,无论在哪个国家,这些数据都是高度保密的。
「受益于欧洲气象中心公布了数十年间的同化数据,我们完成了这个工作。」
不久,谢凌曦更新了回答,「我们接受这个意见。」
「在盘古气象大模型文章中,我们将 NWP 限定为『基于同化数据进行预测的方法』,而不是指代整个『数值气象预报领域』。盘古确实首次在同化数据上超越了传统方法:我们使用了与英伟达 FourCastNet 完全相同的测试环境,确保对比的公平性和结论的可信度。」
研究发布后,谢凌曦团队接到不少交流邀请,包括中国气象局做报告。欧洲气象中心也联系到他们。据说,欧洲气象中心内部有很多讨论,很多现有的技术会被 AI 取代。
也有一些公司联系到郭必扬,探讨文本平台推出相关功能的可能性。「我们的算法还在不断改进,主要从增加模型鲁棒性、收集更多样化数据着手,希望下一代模型更有效。」 接受知乎网友反馈后,这是郭必扬接下来的目标。
二、与「52赫兹鲸」相遇
研究人员争先恐后首发作品,资本也在密集「点杀」AI 大模型人才。
3 月 27 日晚上 11 点,一条消息悄悄在微信里传来:王慧文与袁进辉创立的一流科技达成并购意向,要做中国版 OpenAI。
在大语言模型(LLM)这个领域,曾被很多人认为最不重要的框架,价值已上升到兵家必争。「现在看来,这才是真正潜心搞底层技术的国产典范。」一位关注了相关知乎话题的腾讯 AI 算法专家感叹道。
六年前,袁进辉离开微软亚洲研究院,创业做深度学习框架。当时处境与那只著名的「52 赫兹鲸」无异。
上承算法应用,下接底层硬件,深度学习框架被称为「人工智能操作系统」,是创业公司想都不敢想的蛋糕。彼时,凭借自己巨大影响力和强大推广能力,谷歌的深度学习框架 TensorFlow 已是当时用户最多的深度学习框架(Pytorch 尚在襁褓)。
谷歌这么大公司,好几百人做的事情,你拿什么和别人拼?做底层软件、竞争对手这么很强、还开源……袁进辉当时听得最多的就是「以卵击石」、「螳臂当车」。

因为52赫兹频率比任何已知鲸鱼物种都要高很多,科学家因此认为一头被美军仪器探测到的鲸鱼叫声无法被其他鲸鱼接收得到。
系统软件开发周期很长。从 2016年启动,历经四年到 2020 年 7 月,深度学习框架 OneFlow 才开源。因为承受不了那种高度不确定性、在系统软件成品出来之前也不可能有任何反馈的压力,一些优秀的同事辞职离去。
其实,一旦技术做到系统这么深的地方,能与之共鸣的「鲸」自然会少。在知乎,袁进辉还是找到了和他一样关心底层( fundamental )问题的人。
不少知乎网友在微博时代就知道「老师木」(袁进辉微博网名)。「进辉会在微博上写一些特别好玩儿的消息,大家也在传这个哥们儿到底是谁。」英伟达 AI 计算架构技术总监杨军回忆道。袁进辉创业不久,杨军也在考虑转换工作,两人通过知乎认识了。
在袁进辉心目中,杨军这位集机器学习、深度学习(Deep Learning)话题优秀答主和 2022 年度新知答主于一身的朋友,常年稳定地输出高质量内容,自己也从他的思考中获益良多。
而在杨军眼里,袁进辉也是一个比较聊得来的朋友。杨军自己也比较分析过两大主流深度学习框架,为什么这个阶段还有公司愿意投入巨大资源研发 AI 框架。
2019 年谷歌发布 MLIR,当时深度学习编译器话题备受关注。两人很快出现在「如何看待 Google 关注 MLIR 项目?」问题下,一前一后分享了自己的看法。
袁进辉当时对 MLIR 的评价并不高,感觉编译器之编译器这个概念有点多余。MLIR仅仅为写深度学习编译器提供了一个脚手架,没有解决深度学习编译器里任何具体难题。
杨军更倾向认为 MLIR 是一个好东西。「他对 MLIR 贡献、价值还有缺点分析,让我至今印象深刻。」袁进辉说。
随着思考和讨论的加深,杨军不断用新想法和收获更新最初的回答。袁进辉也保持着认知弹性。2022年,袁进辉再度更新最初的回答,「这两年的发展说明,MLIR提供一个『脚手架』。......是很有意义的。」
人需要一个环境,和味道相近的人交流、碰撞,知乎的属性能够实现这一点。杨军尝试解释这种奇妙的缘分。比如,顺着你的问题、兴趣、文章,自然而然就能判断是不是可以多聊一聊。
OneFlow 开源后,有网友「茅塞顿开,才发现,以前苦苦挣扎的一些问题,还有这种解决方案。」也有人称赞框架设计「清新」。当设计之美被第三方开发者甚至学生心领神会时,袁进辉觉得「好像你写了一本小说,有读者欣赏。」
而当郭必扬因 ChatGPT 陷入焦虑时,最终将他打捞起来的也是这种「人与人的联结」。
他通过知乎组建了一个「孤勇 AI 研究者」群,发现很多同行也生活在 ChatGPT 「智子」阴影下。也是在那里,他找到了测器项目合作者。四十多天的奋战,八个人从头坚持下来,没有一人退出,即使在疫情疯狂的时刻。
他们自称 insignificant researchers,但所做的工作希望是significant work。
在知乎的另一个角落,谢凌曦分享的一段热血岁月已收获 3.2 万个赞。
「如果中国重新开发像 MATLAB、solidworks 这样的软件大概需要多久?」三年前的一个提问让他敲下一段尘封已久的往事。
十几年前,几位清华大学数学系学生想要做一款科学计算软件,比肩应用最广泛的数学软件 Mathematica。招人广告贴到了计算机系宿舍楼,却没什么人关注。当时,从数学系转到计算机系、刚学会 Java 的大三学生谢凌曦申请加入。四个多月写了无数文档,终于做出雏形。一系列荣誉接踵而至,最后拿下「挑战杯」全国特等奖。
「仅一腔热血来做大规模系统,或许我们的项目就算是最好的结果了。没有成熟的商业模式或者健康的生态,项目不可能长期走下去。」多年后,谢凌曦在回答中谈到项目的商业化。
「我们的经验是有正面意义的。它至少证明了:任何一个时代,都不缺少敢于追梦的年轻人。」
三、寻找「百万宝贝」
袁进辉和一流科技被归入的是一个新赛道—— AI 大模型。招聘网站上 ChatGPT 相关岗位开出的薪资最低月入 2 万,最高开出月薪 10 万。levals.fyi 显示, OpenAI 为 AI/ML岗(L5)开出 90 万美元高薪。
仿佛一夜之间,又回到六年前那个资本已经追不上一个接一个的数学博士、计算机博士、统计学博士的时代。彼时,张一鸣微博「悬赏」100 万美金招聘顶尖机器学习人才;在硅谷,一些具备技术专长的高级管理人员如果在谷歌这类大型上市公司工作,年薪(包括股权激励)可达数百万美元(「百万宝贝」)
当时,为了组建公司算法团队,刚毕业就成为图森未来首席科学家的知乎答主 Naiyan Wang (王乃岩)也加入了那场人才争夺。不过他另辟蹊径,在知乎回答「如果你是面试官,你怎么去判断一个面试者的深度学习水平?」时留下英雄帖,并声称,此三题可考察受试者「八成功力」:
CNN 最成功的应用是在 CV,那为什么 NLP 和 Speech 的很多问题也可以用 CNN 来出来?为什么 AlphaGo 里也用了 CNN?这几个不相关的问题的相似性在哪里?CNN 通过什么手段抓住了这个共性?
再补充一个问题,为什么很多做人脸的 paper 会最后加入一个 local connected conv。
这三个问题不是典型教科书上的问题,正如图森未来做的自动驾驶是一个「新物种」,开拓性探索往往需要突破边界,没有可以供参考的先例,更没有现成答案。算法工程师只有洞悉貌似没有关联事物之间更深层的关联,才能去伪存真,让算法工具更好地为我所用,解决现实业务中的问题。
「应该说是个甄别的好题目」当时还是 Facebook 人工智能科学家的贾扬清在回答中揭开其中妙处,「涉及一个很本质的问题就是卷积为什么能够 work。」 回答这个问题的角度有很多,正则化、统计、编程甚至神经科学等,不同角度回答能从不同侧面折射出被试者的深度学习经验。
如果有人对三个问题的回答基本都正确,就说明他对 CNN 理解在线,也是王乃岩要找的人。
一条条接踵而至的回答不断拉长进度条。「接近了,但不准确」、「基本靠谱!下面会让 HR 联系你」、「有兴趣的话,发 CV 到**」,基本沾边的回答,王乃岩都会回应,但更多答案下面是寂静无声。如其所料,八成的人并不清楚卷积神经网络为什么起作用,他们仅仅将它视为一个工具,跑跑开源代码。
一位日本名校毕业的硕士引起了王乃岩的注意。「本科是清华大学的,当时在日本读完硕士正在找工作,他的答案跟我心里想的很接近。」王乃岩说。接下来的面试感觉也很好,立刻给他发了录用通知。这是图森未来招到的第一位算法工程师员工。如今,他已经是公司日本业务负责人。
互联网使得地理意义的「附近」已经转化为数字意义的「附近」。你可能不了解一步之遥的邻居,但对复杂技术构造出来的抽象系统高度信任,比如知乎。对于不少名副其实的 AI 创业团队来说,当他们需要更多依靠个人渠道抢人时,这里往往是个不错选择。
就在王乃岩寻找算法工程师时,袁进辉也在为开发深度学习框架求贤若渴。注册知乎后,袁进辉做的第一件就是为他们的工作做「广告」。有的人看到袁进辉的文章和互动才知道除了互联网大厂,在创业公司也能做底层架构。好几位一流科技的全职同事包括实习生,都是这样从知乎上招到的。
更多时候,袁进辉会主动出击。浏览到有意思、充满真知灼见的回答,他会去看对方的 Github,力求较为全面的了解。虽然没能「挖到」一些心仪的人,但大家慢慢也成了朋友,会见面交流一些看法。
在自己领域做得越久,写得文章更多、问题互动更多,社区反馈也更好。一位面试过多家公司实习岗的本科生在「国内有没有本科在读适合的系统或编译器实习岗」中回复说:
其中我看说你对技术/coding 有极致的追求,我觉得袁老师的 oneflow 是一家非常有深度的公司,当时面试我直接和oneflow的面试官聊了一下午C++和并行计算,从各种优化技巧比如sso,stack/dynamic memory,到各种模板,函数式风格编程,以及吹/黑最近的一些ml system的论文。
平时一向低调的王乃岩在知乎上特别活跃,写文章做技术分享,也是深度学习、机器学习和人工智能领域优秀答主。关注他的粉丝中不少是在读计算机专业学生,不少人也是通过「关注」最终成为图森未来的一员。图森未来现在的算法岗位有不少本科生,这在很多公司是不可能发生的。
其实,他们非常优秀。在王乃岩看来,如果按照互联网大厂招聘模式,一些没有光鲜教育背景也没有闪亮论文的「璞玉」会被那些硬标准直接筛掉。
「很多时候,他们已经有什么没那么重要。我们更在意这个人的基础能力和潜力,有没有自我思考和对技术的热忱,哪怕他是一个本科生。」
现在,王乃岩仍然会从知乎上寻找人才。但与创业初期不同的是,更多是被动去找。「不论是关注的人还是信息流、推荐,已经帮我过滤掉很多无效信息。」王乃岩说,「真有用的信息,会在信息流里反复出现。」
平时他会浏览一些热门话题,看到有意思的回答也会点击进去了解更多。契合公司需要,他会转给人事部门。
无论技术如何发展,Top1% 的人不会变,对技术的热忱、坚定的信念仍然是他最看重的。
四、时光回响
ChatGPT 发布后,知乎答主「Trinkle 」突然现身「如何评价 OpenAI 的超级对话模型 ChatGPT?」问题下,公开自己「有幸参与 ChatGPT 训练全过程」并呈上对未来世界的想法:
「可以开始想象 AGI 之后的世界了,我已经想了几个月了。......」
回答底部, 在 OpenAI 官网致谢内容里,「Jiayi Weng」出现在一串贡献者名单中并被高光,人们逐渐知道「Trinkle 」叫翁家翌。他是 OpenAI 近两年来第一位硕士毕业应届生员工,也是团队年纪最小的研发工程师之一。
现在,回答已收获 3000 多个赞。很少有人知道他一度觉得自己靠不近 OpenAI,「毕业投简历时,也认为自己靠不近。」他说。
翁家翌从初一开始接触编程,当时重心在奥数上,学编程不过是为了拓展数学思路。真正感到编程魅力是在高中进入福州一中后。
当时,他很喜欢卡常数。「给一个固定问题,你可以写一堆代码,写相同的算法,有相同的时间复杂度,但我可以协调一些东西,让相同的算法比别人跑得快。」这种 PK 让他很有成就感。
当时福州一中信息组有一个内部判题系统( OJ )在线测评,里面有各种历史记录,翁家翌经常刷到第一才会停下来。
高二时,翁家翌彻底将重心从数学转到编程。为了能上「清北复交」,他决定参加信息学奥赛。当时信息组有不少同学在玩知乎,他也注册了一个账号。那时,他不会想到几年后会成为许多网友眼中「高三开始玩知乎的天才少年」。
阿尔法狗战胜李世石的那一年,翁家翌也如愿进入清华大学。因为信息学奥赛发挥失常,他靠大一达成全系绩点前十成就转到计算机系。大二时与强化学习结缘。
与朱军教授见面一对一聊天时,朱军教授问他想做什么?组里有三个方向:贝叶斯、对抗训练和强化学习。虽然选择了强化学习,但他当时并不知道什么是强化学习。
「一开始以为和做 GAN (对抗训练)差不多。」选完后才知道要打游戏。为了入门,他后来玩了很多游戏。
如果说高中时的翁家翌主要在知乎潜水和搜集信息,进入清华大学后,他有了更多分享的欲望。或许这与他高中就立下的人生目标有关——获得更多的影响力,帮助更多的人。这些都需要与机器、与人建立连接。
他在知乎发布的最重要工作是大四毕业设计强化学习算法库Tianshou(天授),也是至今对他影响最大的研究。后来能进入 Open AI 工作也受益于这次「一作」经历。
最初版本的 Tianshou(天授)是两年前实验室四个人用 Tensorflow 写的,速度非常慢,没什么人用。他曾试着重构里面部分代码,但没用。后来干脆全部推倒重来。结果发现,精简框架带来的收益不仅是代码层面上的,还有性能上的。
工作发布后,有眼尖的网友发现了这点:
「如果同样的算法比如 dqn+同样是 pytorch,为什么你的代码会快那么多?感觉除了这两部分其他代码的逻辑都类似啊。」
「代码也是有灵魂的(逃,就是实现细节吧……」他说。
那一次「真正让我意识到,如果要创造影响力,你应该去写一些基础的东西,或者在工程上有所建树,而不是说在一些 research 方面有所建树。」他说。
AI 领域有很多低质量的实现,很可能是因为研究者工程能力不够。如果把一些工程方面见解带入研究,会有不一样的收获。
除了扩大工作影响力,翁家翌也热衷参与清华大学本科生活有关的话题。「选择在清华大学念书你后悔吗?」、「在清华大学读计算机科学与技术专业是一种什么体验?」问题下都留下过他的痕迹。一段走出迷惘困惑,逐步坚定方向的过往,让他的回答至今人气不减。
「感觉这样的心态正是我需要的,快要被你清 fly bitch 折磨疯了。」一位清华校友敲出自己的心声。
「学会承认自己不如人,与自己和解。」翁家翌写道。高中时,他就发现不管自己多么努力,总有人站在更高地方俯瞰自己,无论是信息学奥赛还是文化课。大学最初两年亦复如此。英语比不过室友,一些听不懂的课,总有人不用学都能过。
「要学会定义评价指标,不再随波逐流。」这是他的建议。到了大三,翁家翌彻底改变对自己的评价指标,回归初心。
他不再按部就班地刷 GPA、「卷」论文,更喜欢做一些「无用」但有趣的事情,例如写代码。「写个人项目的时候我觉得我在创造一件艺术品。」对写代码和开源项目的热爱也影响了后来出国留学的决定。
每迈向一个新的站点——春招、秋招、博士申请、国内找实习岗——他都不吝于分享自己的经历,不管是多个 offer 在手的晴朗、还是博士申请被吃「全聚德」的阴郁,每次回答都收获很高人气。
现在,翁家翌已经贡献了 33 个回答,发布了 3 篇文章,累计了 2 万多个关注者,总共获得 28,966 次赞同。这些数字或多或少量化出「用自己的力量帮助更多的人。」
在「你的 2022 秋招进展怎么样了?」问答下,他共享出投了上百家公司的经验并在这个近千高赞回答的末了写,下「选择大于努力。」
如果没有做出那些基于当下环境的最优决策,没有参加信息学大赛、选择强化学习,也没有申请出国读书,又或者坚持读博,还有可能走到今天这个节点吗?
努力弥补不了决策失误。Google 目前为什么在 AI 上落后 OpenAI 一大截?采访时他反问道,然后又径直给出答案,「因为他们选择了另外一个方向,与 OpenAI 不同的方向。」
最近,有人问「有什么方式加入 OpenAI 做研究吗?......我认为在公司做 research 似乎是更有效果的事情,可以给我一些建议嘛。」
他将当初这个高赞回答的链接转给了对方。

壮观的珊瑚礁是珊瑚虫们努力多年的大工程。珊瑚礁仅占全球海床洋底0.5%的面积,却是四分之一以上海洋生物的家园。
在知乎,每一个科技「知乎er 」犹如渺小又神奇的珊瑚虫和虫黄藻,借由提问、回答和关注,彼此交换能量信息,周而复始,一种更加高级的系统出现了,引来更多前沿科技「物种」栖息,包括一些顶级科学家。
知乎战略副总裁、社区业务负责人张宁曾表示,站内从事科研学习和工作的人群总数高达 544 万人,仅科技互联网领域,就日均图文生产量两万多篇,在数学、物理、天文、人工智能等多个领域的回答、文章和视频数都超过了 100 万篇。
ChatGPT 后,百度「文心一言」发布、GPT-4 发布、微软集成 AI 对话功能等一线事件发生时,业内大咖都在第一时间聚此讨论。
3 月 28 日,华裔数学家张益唐在知乎上发出邀请:「我将应哈佛大学和欧洲几个大学的邀请,做一次直播,主题为:Non-positive sequences in analyticnumber theory & the Landau-Siegel zero(解析数论中的非正序列&朗道-西格尔零点。」
这一次,在知乎,你又可以听到号角的声音。返回搜狐,查看更多
责任编辑:

0 留言