



蛋白质功能注释,即通过对蛋白质序列、结构的分析确定蛋白质生物功能,在生物医学、药物研发等领域意义重大。然而,蛋白质的功能注释仍然面临着巨大挑战。
近年来,测序技术和宏基因组学的发展帮助人们从各类生物体中发现了大量蛋白质序列。目前UniProt知识库已对大约 1.9 亿个蛋白质序列进行编目。然而,这些蛋白质中只有不到 0.3%(约 50 万)经过人工审核,这其中也只有不到19.4% 得到明确的实验证据支持。因此,蛋白质功能注释高度依赖于计算注释方法,但现有计算工具自动注释的酶中约有 40% 被错误注释。这样的困境严重阻碍了生物医学领域的发展。
日前,美国伊利诺伊大学厄巴纳香槟分校Huimin Zhao(赵惠民)课题组在一篇发表于《科学》(Science)的研究论文中给出了解决方案。该研究开发了一种名为CLEAN(全称Contrastive Learning enabled Enzyme Annotation,即“启用对比学习的酶注释”)的机器学习算法,实现了高准确性、高可靠性、高灵敏度的酶功能预测。

为了理解最新研究预测酶功能的方法,让我们从酶的编号体系说起。酶学委员会(Enzyme Commission, EC)编号是用于区分酶功能的最常用编号分类法,酶能催化哪些反应,就体现在EC编号的4组数字中。之前的机器学习算法将EC编号预测任务构建为多标签分类问题,受到训练数据集规模的限制,尤其是对研究较少、未被标记的酶和具有多重功能的混杂酶表现不佳。
与之前的机器学习算法不同,CLEAN采用了对比学习框架。其训练目标是学习欧几里得距离反映功能相似性的酶的表示空间,即具有相同EC编号的氨基酸序列具有较小的欧氏距离,而具有不同EC编号的序列具有较大的距离。
对比损失(contrastive loss)用于在监督下训练模型。在训练过程中,训练数据集中的每个参考序列(anchor)都被采样得到一个具有相同EC编号(正)的序列和一个具有不同EC编号(负)的序列。学习目标是一个对比损失函数,它将参考序列和正序列之间的距离最小化、与负序列之间的距离最大化。
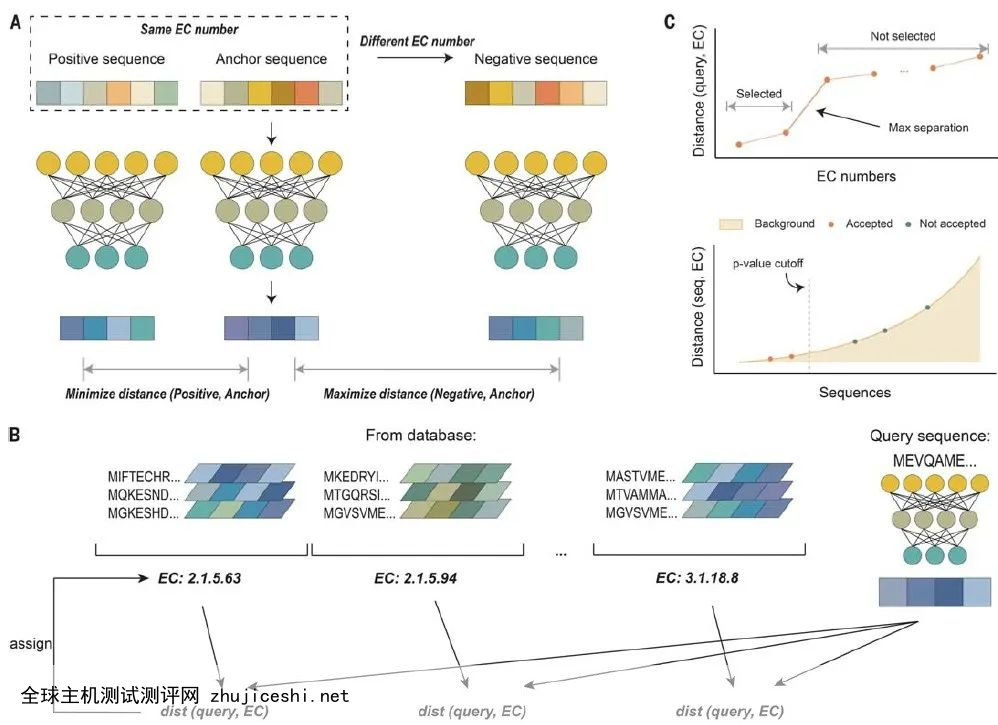 ▲基于对比学习框架的CLEAN示意图(图片来源:参考资料[1])
▲基于对比学习框架的CLEAN示意图(图片来源:参考资料[1])通过对三组不同数据集的模拟验证,结合三种显示出“冲突”功能的卤化酶MJ1651、TTHA0338和SsFlA的体外实验结果,研究发现CLEAN相对于其他常用计算工具具有更好的预测准确度,能够高质量的完成以下任务:注释未被充分研究的酶,纠正错误标记的酶,以及识别具有两个或更多EC数字的混杂酶。
总体而言,CLEAN是预测查询酶催化功能的强大工具,可以极大地促进功能基因组学、酶学、酶工程、合成生物学、代谢工程等领域的研究。最重要的是,CLEAN在预测未充分研究的蛋白质方面的卓越性能将极大地扩展生物信息学工具箱,从而为未来详细的机制研究奠定基石。
对于接下来的工作目标,赵惠民教授谈到:“我们计划拓展CLEAN,用于对受体、转录因子等非酶蛋白质的功能预测,进而预测自然界所有蛋白质的功能。此外,我们还将尝试预测酶的其他功能,例如稳定性、底物专一性与选择性。我们还将结合CLEAN与AlphaFold,提升对所有蛋白质功能的预测准确度。”
CLEAN网页版的预测工具已上线https://moleculemaker.org/alphasynthesis/。
美国伊利诺伊大学厄巴纳香槟分校(UIUC)的赵惠民教授为该论文的通讯作者;UIUC化工系博士生于天浩和基因组生物学研究所博士后崔海洋为共同第一作者。康奈尔大学李迦南、佐治亚理工学院助理教授罗宇楠、UIUC博士后姜广德为论文共同作者。该论文还得到了UIUC博士后黄春帅和张郑一的技术支持以及美国国家科学基金会(NSF)的资金支持,在此一并表示感谢。
封面图来源:123RF
参考资料:
[1] T.H. Yu, H.Y. Cui et al., Enzyme function prediction using contrastive learning. Science (2023). DOI: 10.1126/science.adf2465

0 留言