



不是那样。
题目称:
现在chatgpt已经能够很好地处理语言,理解里面的逻辑,理解人类问题的意图,并拥有上下文的记忆和连贯性,能够很好地表达输出。不是那样。这个语言模型和其他大型语言模型一样完全不理解语言、逻辑、问题的意图,不存在什么记忆和表达,它们只是对训练文本里排列组合的字词的出现率进行统计、按照你输入的东西和统计出来的出现率排列字词来给出回复,排列得并不好。你可以轻易诱导它犯错,而且它会犯许多出乎你预料的错,例如 27 到底是不是质数。
当然,你可以认为能正确使用就是理解。那么,这程序现在犯的大量错误就是它不理解语言、逻辑、问题的证明。
程序对上下文的引用是规模小得多的模型就能做到的反复调用,毫不神秘。Character.ai 在这方面经常做得更好。
你可以声称人类神经系统的突触连接网络也能解释为基于统计(人脑可能有基于 talin 蛋白的机械计算和基于某些分子自旋的量子特性,这些也可以模仿),可以声称人类幼体在语言和逻辑上的表现跟这模型一样差或更差。这不改变三岁小孩能在你眼前学会 27 不是质数且不会反复扯这个淡的事实。
此外,你不觉得机器更迫切地需要与外部世界互动的身体和感官而不是更多的文字序列吗?
题目称:
虽然它的训练包含了大量现成的资料讯息,但它给出答案时并不是去资料库里面实时搜索,就好像我们人考试时并没有去翻答案一样。这样的一个智能体,难道不是跟人已经很接近了吗?不是,你根本就不明白。
一般人并不会因为进行开卷考试或考试作弊、照着书抄而自称自己变得更像程序了。
“按概率给出形式上在资料里没有的输出”和智能无关。
此外,调用本地存储和去网上搜没有真正的区别。
题目称:
虽然现在确实能找到它的很多问题,但要看它的机制是怎样的,它还有多少成长空间。我们人类的逻辑基本都是建立在语言之上的,如果它有能力从语言中学习和整理逻辑,随着模型参数的持续增长以及类似提示工程师这样的智能挖掘/训练,它必将越来越复杂,逻辑能力越来越强,越来越智能,并且这个演进应该是加速的。不是那样。就不用说你对逻辑和机器学习的错误理解了,训练大型人工智能模型的成本已在数量级上逼近人类有意愿拿出来的最大成本,若人类的总功率增量不能加速,模型参数的持续增长无法加速。
高性能计算设备是能源密集的,现在的 AI 已经接近人类社会能承受的限度[1]。训练一个错误率小于 5% 的图像识别模型,硬件和电费等成本要花掉 1000 亿美元,产生的碳排放与纽约市一个月的碳排放量相当。训练错误率小于 1% 的图像识别模型就更贵、更耗能了。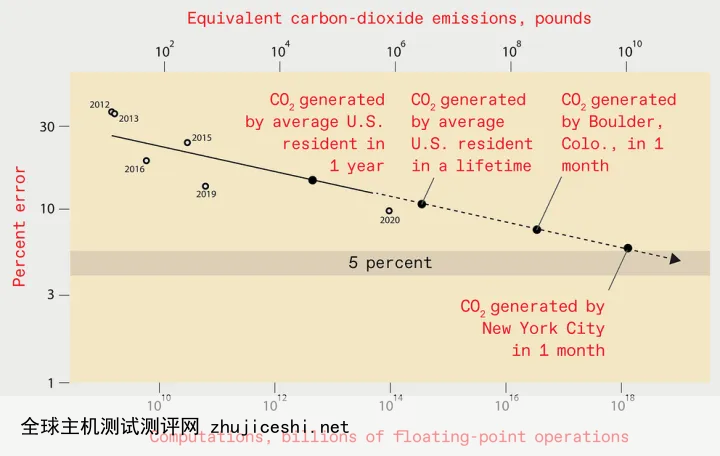
题目称:
但我看到似乎没有人将它和强人工智能关联到一起讨论,即使是专业人士。不少人还是像AI尚未碾压人类顶尖围棋手时那样只去找它当前的薄弱点去轻视它。这是为什么呢?因为大型语言模型跟强人工智能没有半点关系。

0 留言