



IO密集型
指系统的CPU性能相对硬盘、内存要好很多,平衡负载值会很高,但是cpu 的us 和ys 负载不是很高,因为平均负载是由 cpu+ IO 共同组成 。而 Cpu 内存,外设 网络 大量的换入换出会导致IO密集型
可以理解为简单的业务逻辑处理,比如计算1+1=2,但是要处理的数据很多,每一条都要去插入数据库,对数据库进行频繁操作。
模拟磁盘IO 密集型
执行命令
stress-ng -i 6 --hdd 1 --timeout 150
开启1 个worker 不停的读写temp文件同时开启6个worker不停的调用sync系统调用提交缓存,持续运行150s
后台启动node_exporter
# 后台启动node_exporter nohup ./node_exporter &监听机器启动 grafana 和 prometheus
#启动 grafana systemctl restart grafana-server #后台启动 prometheus nohup ./prometheus &
启动grafana
启动 promethues
执行 stress-ng -i 6 --hdd 1 --timeout 150 查看监控
top查看 wa非常高、sy不是很大, buff/cache有增大 ,导致 load average 开始增大
us 用户进程空间中未改变过优先级的进程占用CPU百分比 -用户进程 sy: 内核空间占用CPU百分比 -系统进程 ni: 用户进程空间内改变过优先级的进程占用CPU百分比 -由内核进入非内核的状态切换的耗时 id: 空闲时间百分比 wa:空闲&等待I/O的时间百分比 -资源不够时导致cpu处于等待时间 hi: 硬中断时间百分比 -程序切换 si: 软中断时间百分比 -管理员自愿切换 st:虚拟化时被其余VM窃取时间百分比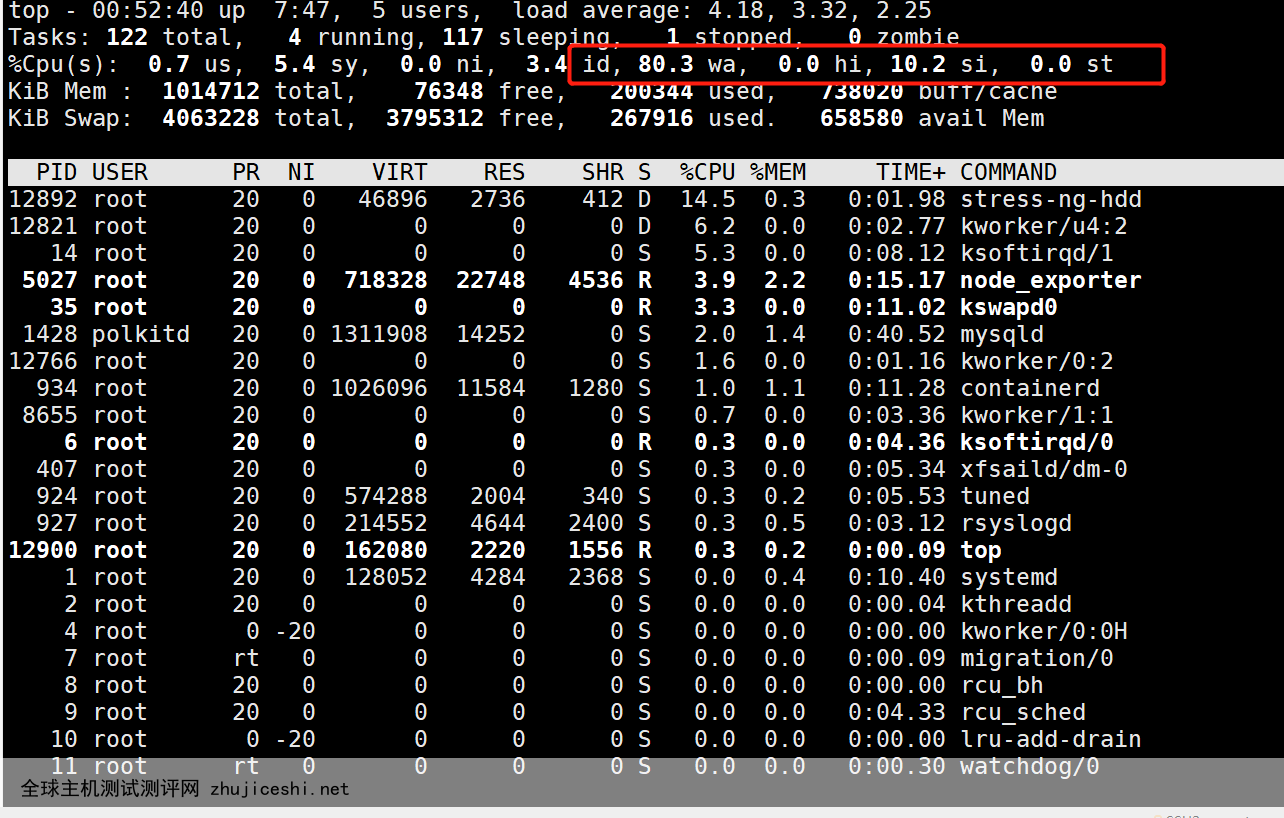
vmstat查看系统内存 bo开始升高
mem free开始减少, cache开始明显的增大, bo 有明显数据, 说明有大量磁盘数据交换
memory : swod显示多少块被换出磁盘 free显示剩下的空闲块 buff正在被用作缓冲区的块 cache正在被用作操作系统的缓存 IO: 显示了多少块(BYTE)设备 读取 (bi)写(bo) 通常反映了硬I/0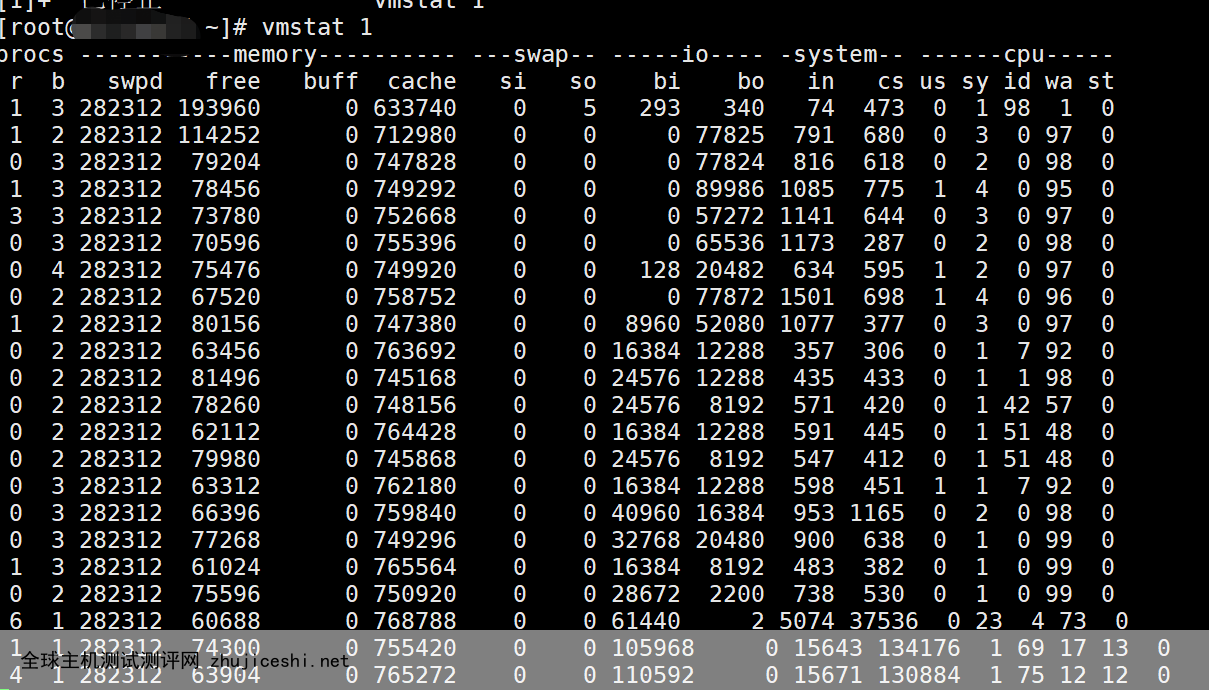
监控平台查看
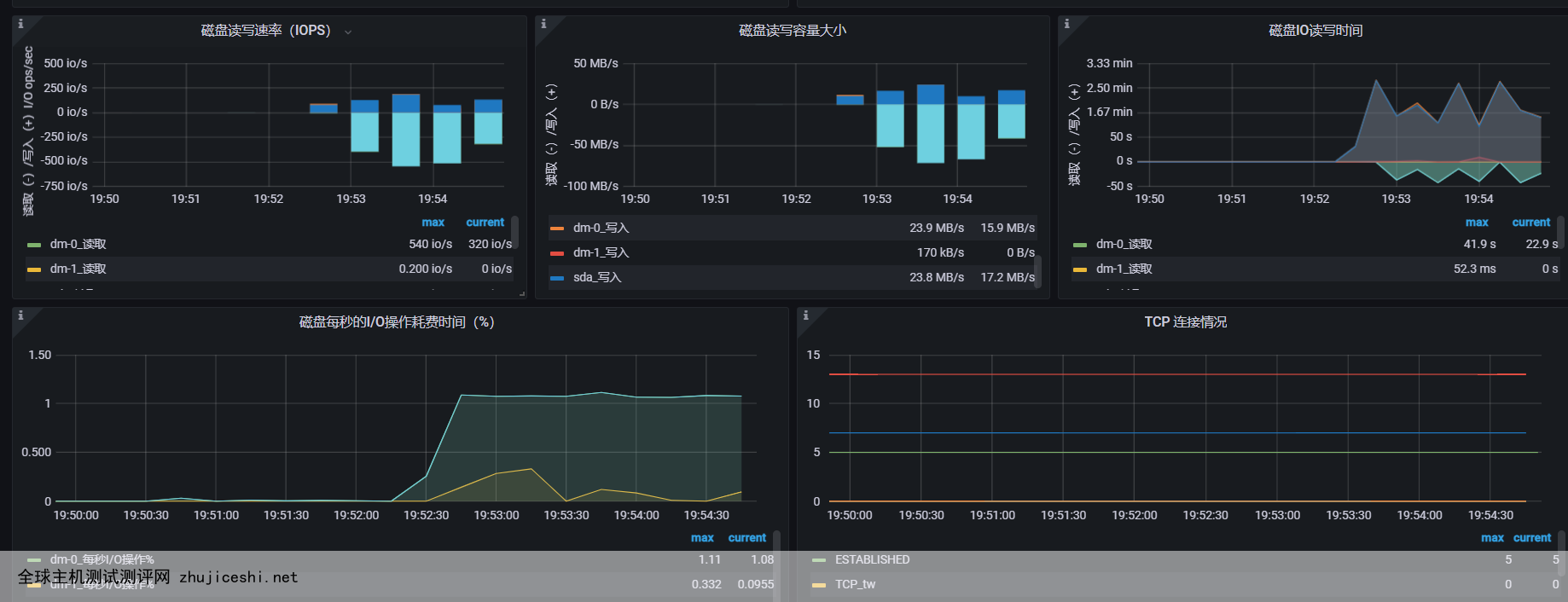
io操作达到了100%
通过mpstat的iowa 的值 可以知道系统负载高的原因是因为IO问题导致,所以需要找到对应那个线程导致的磁盘读写高,这个时候可以通过 pidstat 命令查看
mpstat -P ALL 3 3 秒获取一次所有的监控数据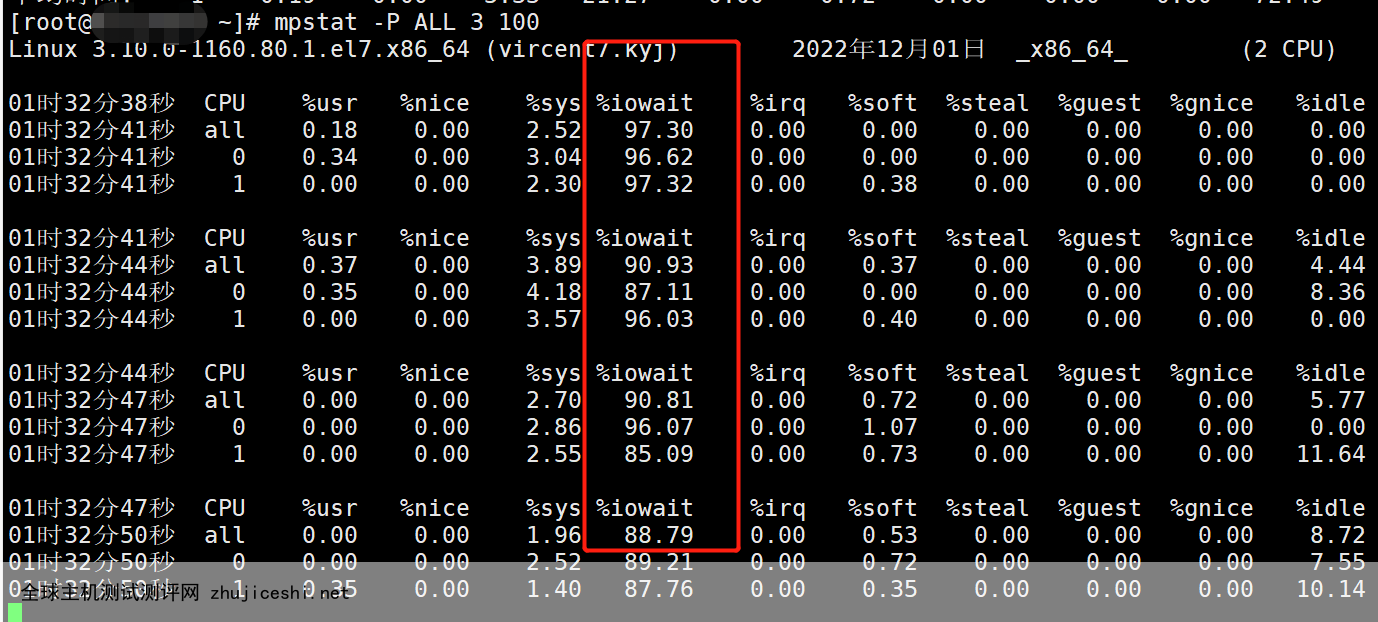
pidstat -w 1 查到 stress-ng-hdd这个进程的 自愿上下文切换数据比较大,pid的值 进程id
优化方案
更换磁盘迁移到io性能更好的服务器启动另外一个IO性能比较好服务器安装数据库 给数据库做读写分离。在性能好的数据库读操作,在本机性能差的数据作写操作 要么 减少io操作如 减少日志打印频率定位问题代码
思路:通过pidstat 或者top 找到具体进程id之后, 找到线程 进程 id,然后把线程id进行16进制转换, 进程id日志打印出来,过滤出线程id(16进程)

0 留言