



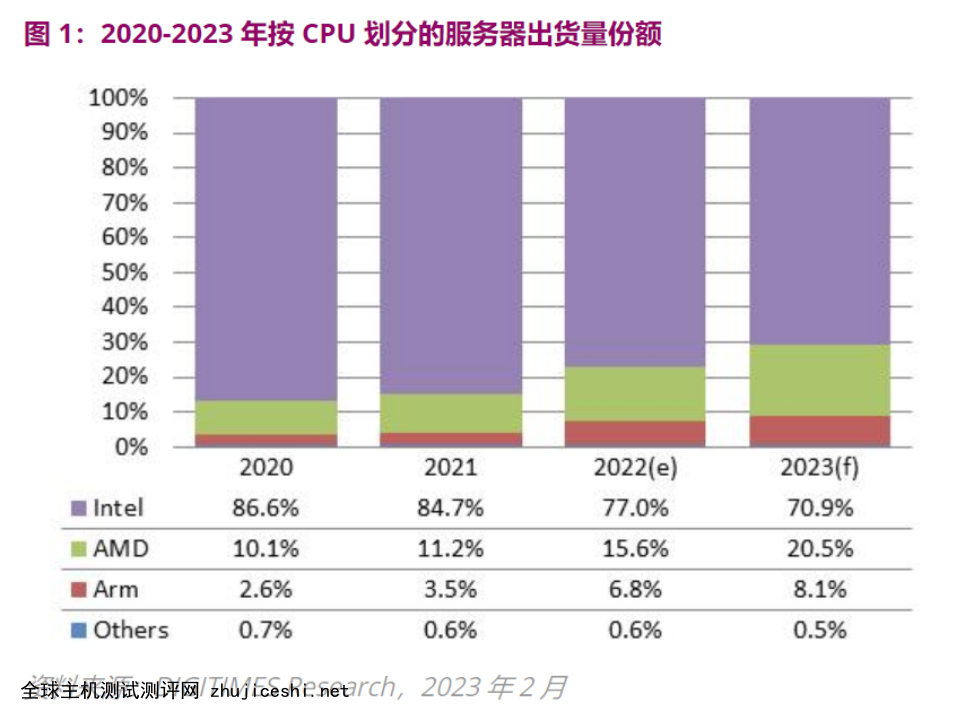
过去几年,AMD 和 Arm 在服务器 CPU 市场上一直在追赶英特尔,随着数据中心运营商和服务器品牌开始从数量上寻找解决方案,AMD 赢得的份额利润在 2022 年尤其大。根据主要关注服务器行业的 DIGITIMES Research 分析师 Frank Kung 的说法,第二大制造商的增长优于长期领先者,他预计 AMD 的份额将在 2023 年超过 20%,而 Arm将获得 8%的份额。
价格是导致数据中心运营商和服务器品牌转向 AMD 的三大驱动因素之一。比较核心数、时钟速度和硬件规格相似的AMD和英特尔的服务器CPU,前者的大部分产品价格标签比后者至少便宜30%,差异甚至高达40%以上,Kung说。
这种差距对服务器公司产生了关键影响,因为他们通常会大量采购 CPU,而选择 AMD 的解决方案将大大降低成本。Kung 指出,由于英特尔和 AMD 的处理器都是基于 x86 架构,因此兼容性不是服务器公司需要担心的问题。
AMD CPU 的高内核数也使其非常适合服务器环境,因为 CPU 的内核数越多,它可以提供的服务能力就越强。AMD 的 96 核 Genoa 架构 EPYC 处理器于 2022 年第四季度推出,128 核 CPU 将于 2023 年上半年首次亮相,而英特尔目前在核心数方面的最佳产品仍停留在 60 个。
台积电的支持是第二个驱动因素。AMD的服务器CPU全部采用台积电最新制程制造,性能表现一流,得益于台积电的先进技术和高良率,AMD没有出现错过产品上市时间的问题。然而,英特尔并非如此。
第三个驱动因素是英特尔正在内部制造其所有顶级 CPU。来自英特尔上游供应商的信息显示,过去几年英特尔自产技术不稳定,服务器品牌商和数据中心运营商经常看到英特尔推迟其新服务器平台的量产计划。
在数据中心运营商中,微软和谷歌最热衷于采购采用 AMD 解决方案的服务器。目前,两家云服务提供商超过 30% 的服务器订单都是基于 AMD 的型号,而在服务器品牌中,惠普企业 (HPE) 更热衷于采用 AMD 技术的服务器。
Kung 表示,就市场份额增长而言,2022 年基于 Arm 的处理器在服务器市场的渗透率比基于 AMD 的处理器要慢一些,到 2023 年增长将进一步放缓。然而,从长远来看,基于 Arm 的处理器仍将具有大幅增长的潜力。
尽管基于 Arm 的 CPU 与 AMD 和 Intel 的基于 x86 的 CPU 相比可以实现并驾齐驱的计算性能,同时功耗要低得多,但兼容性是目前它们最大的弱点。
由于大多数服务器程序都是基于 x86 架构设计的,因此问题不太可能得到解决,直到更多基于 Arm 的服务器开始出现,吸引更多中间件开发人员加入市场并编写解决方案来为 Arm 系统翻译 x86 代码。
然而,数据中心运营商和服务器品牌仍然对 Arm 处理器在服务器市场的发展持积极态度。亚马逊和阿里巴巴已经在 2022 年之前开始开发基于 Arm 的产品,微软和谷歌也在 2022 年开始使用 Arm 产品的项目,HPE 正在扩大其对基于 Arm 的服务器的采用。英伟达现在正在推动其 GPU 支持 Arm 架构,而 Ampere 正在开发基于 Arm 的芯片。Kung 补充说,在未来几年,随着大型数据中心和边缘计算服务器的需求激增,预计 ESG 将为 Arm CPU 带来机遇。

苏姿丰:下一个挑战是能效
“在接下来的十年里,我们必须将能源效率视为最重要的挑战,”AMD 首席执行官Lisa Su(苏姿丰)在旧金山举行的2023 年 IEEE 国际固态电路会议(ISSCC) 上对工程师们说。
尽管摩尔定律放缓,但其他因素推动主流计算能力大约每两年半翻一番。对于超级计算机,翻倍的速度更快。然而,Su 指出,计算的能源效率并没有跟上步伐,并指出未来十年后的超级计算机需要多达 500 兆瓦的电力。
“这与核电站差不多。” Su说,没有人真正知道如何实现下一次超级计算机能力的千倍增长,但它肯定需要提高系统级效率,这不仅意味着芯片上的节能计算,还意味着高效的芯片间通信和低功耗内存访问。
在计算方面,Su 指出了处理器架构、先进封装的改进,以及更好的硅技术。这种组合可以使行业历史性的每瓦性能增长率提高一倍以上。例如,Su 将MI250X加速器 GPU与其前身 MI100 进行了比较,该 GPU 落后于五台最高效的超级计算机中的四台。较新的芯片提供 4.2 倍的性能和 2.2 倍的效率。其中,chiplet 设计和集成贡献了近一半的性能提升和约 30% 的效率提升。
“我们最近拥有的最大杠杆可能是使用先进的封装和小芯片,”她说。“它使我们能够比以往任何时候都更紧密地将计算组件结合在一起。”据 AMD 称,基于小芯片的系统中的 3D 互连可以传输大约 50 倍的比特/焦耳能量,就像主板上的铜连接一样。使用称为 3D V-cache 的技术,AMD 计算小芯片现在可以在其上堆叠额外的 SRAM 以扩展其缓存的大小。
Su 指出的另一个节能因素是所谓的领域特定计算,Su 将其描述为“为正确的操作使用正确的数学”。由于 8 位浮点运算的能效约为 64 位浮点运算的 30 倍,因此 GPU 和其他 AI 加速器芯片的制造商一直在寻找尽可能使用此类低精度运算的方法。特定领域的架构约占 MI250X 性能和效率改进的 40%。
AMD 希望从其下一代 MI300 中再获得 8 倍的性能提升和 5 倍的效率提升。
但Su说,处理器创新本身不足以实现 Zettascale 超级计算。由于 AI 性能和效率的提高超过了主导超级计算机物理工作的那种高精度数学的收益,因此该领域应该转向可以利用 AI 效率的混合算法。例如,人工智能算法可以快速高效地逼近一个解,然后通过高精度计算来填补人工智能答案与真实解之间的差距。
*声明:本文系原作者创作。文章内容系其个人观点,我方转载仅为分享与讨论,不代表我方赞成或认同,如有异议,请联系后台。

0 留言