



说起超级计算机或面向企业的产品,人们的第一印象可能是“高端大气上档次”,和我们的日常应用离得很远。实际上超算的发展,或者说组成超算的处理器以及相关企业级产品的发展,很大程度上代表了整个行业发展的前瞻信号。现在,超算市场的处理器产品,逐渐从只使用CPU,变化为加入大量专用模块,现在组成超算的部件包括了CPU、GPU、IPU、VPU以及各类加速器,甚至FPGA都开始频繁出现超级计算机或者企业级服务器中。AMD、英特尔和英伟达三巨头,业已推出多款整合“XPU”的产品。那么,这会是超算或企业级处理器市场未来的发展趋势吗?为什么行业发展要朝向DSA(领域内专属微架构)的方向迈进呢?
复合类新产品出现
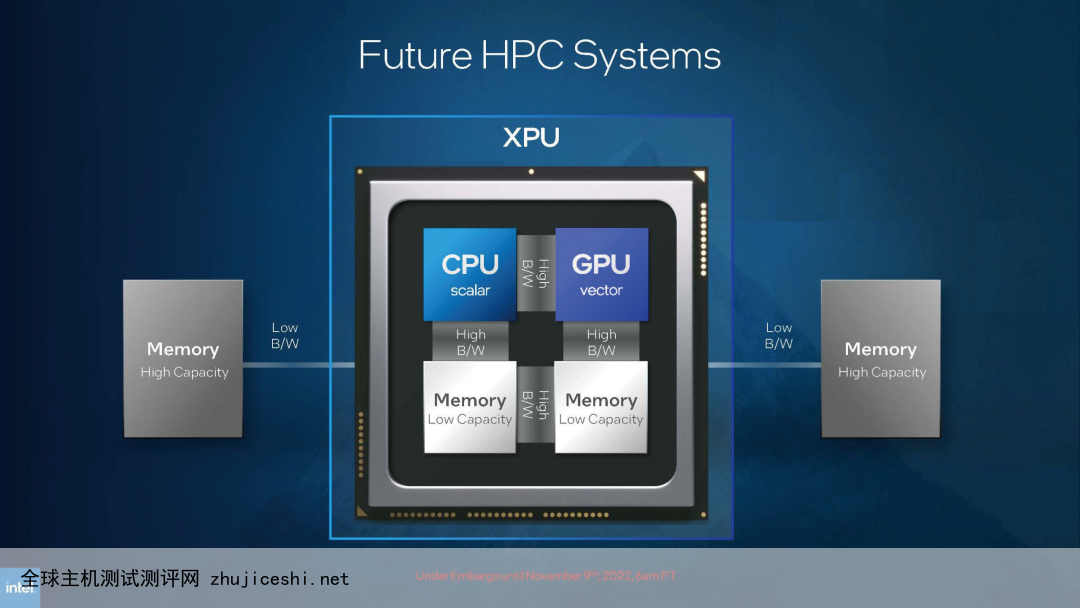
在2022年的英特尔投资者大会上,英特尔展示了一个全新针对AI和HPC市场研发的、代号为“Falcon Shores”的全新芯片。它和英特尔现有的CPU、GPU有所不同,英特尔称其为“XPU”。所谓“X”,是“混合”的意思,英特尔宣称整个Falcon Shores将拥有可扩展的、可根据需求配置的CPU和GPU部分。在英特尔的计划中,这种复合类型的XPU,将拥有比现在产品高5倍的每瓦特性能、内存容量和内存带宽。
根据英特尔规划,Falcon Shores将在2024年推出,采用英特尔的20A或者18A工艺。英特尔将采用Chiplet技术,以不同的Tile也就是功能片的形式,来实现对CPU、GPU以及其他加速模块的灵活配置,以更大程度地贴近客户的需求。
随后AMD在CES 2023上发布了全新的数据中心处理器Instinct MI300。作为面向下一代数据中心的超大规模处理器,它包含了13个Chiplet芯片和高达1460亿晶体管,是AMD有史以来推出的最强大的芯片。
在AMD的官方介绍中,Instinct MI300将在2023年下半年推出,整体架构包括24个Zen 4核心的CPU和CNDA 3架构的GPU,超大容量Infinity Cache,还有高达8192bit、128GB容量的HBM3超高带宽内存。此外它还支持第四代Infinity Fabric总线、CXL 3.0总线、统一内存架构以及全新的数据格式等。AMD官方宣称对比上代产品的性能提升高达8倍,可以满足百亿亿次计算的需求。

AMD发布全新的Instinct MI300产品,结合了多个CPU和GPU核心。
AMD的产品实际上是专为AI或者HPC场合设计,它将CPU、GPU以及一些加速器融合在一起,希望能够带来效能、性能方面的飞跃式提升。与此类似的是,英伟达在这方面也做出了自己的努力。不过它并不是依靠Chiplet或者其他的技术,而是直接将两个全新的独立芯片——Hopper GPU和Grace CPU布置在一个PCB上,并采用自家的NVLink实现芯片到芯片的高带宽互联(高达900GB/s),同时配合了高带宽的HBM3存储和LPDDR5X等。英伟达宣称,在高带宽IO以及NVLink网络的支撑下,这款名为NVIDIA Grace Hopper Superchip的芯片(将在2023年上半年发布),将为运行TB级别数据的应用程序带来高达10倍以上的性能提升。
显然,随着AMD、英特尔和英伟达全新一代产品的发布,下一代超算的形态可能会发生明显的变化。现在我们看到超算Top 500排行榜上,产品CPU、GPU的型号都是很明确的,比如AMD EPYC处理器、英特尔Xeon某型号,GPU则是英伟达H100或者其他型号等。但是下一代的超算,如果采用Falcon Shores或者Instinct MI300的话,那么CPU和GPU的具体型号就可能不存在了,统计时就只能标注CPU或者GPU的核心数量了。
走向DSA化的超算
从多款产品的发展情况来看,集合CPU和GPU的力量在单一芯片上,并且拥有诸如统一内存寻址这样的特性成为趋势。相比传统的PCIe总线连接CPU和GPU而言,采用Chiplet技术或者其他的总线连接技术,能够极大地缓解数据传输中的带宽瓶颈。
当然,数据在超算中的不断搬运、存储带来的能耗或者对效能的影响是行业所关注的一个方面,AMD、英伟达和英特尔正在这方面持续努力。而另一方面的问题,可能更值得我们去思考,那就是为什么三大厂商都开始利用Chiplet技术(或者类似的设计)将CPU和GPU集成在一起?在CPU向多核形态发展之后,下一步是什么?
这样的趋势在桌面PC上可能刚刚开始出现,比如我们的CPU核心才刚开始有最多32个,即使线程撕裂者这样本来面向给服务器市场的处理器,其核心数量也多在64~96个。而在异构类型的超级计算机没有广泛普及之前,一整套超算往往会有数万到数十万个CPU。如此多的CPU在很大程度上极大地提升了超算的性能,但是随着CPU数量不断提升,新的问题出现了。
一方面是CPU数量上升到一定程度后,边际效应开始显现,继续增加CPU数量带来的性能提升不再是线性提升。这涉及很多问题,比如CPU中计算单元数量相对较少、超多的CPU核心在编程上存在困难等。
另一方面,更多的CPU带来了性能功耗比的下降,从而导致超算功耗变得越来越大,甚至难以控制。与之相应的是超算本身的功耗、散热所需功耗等叠加起来,使得相应产品的制造难度和使用成本变得难以控制。因此从超多核心CPU到异构超算,再到超算下一步的发展方向,我们恐怕需要从三个定律来了解一二。
三大定律解读
首先是摩尔定律。很难否认,摩尔定律带来了几乎规律增长和看似无限的晶体管资源,使得人们对晶体管资源的使用效率开始逐渐降低。麻省理工团队做过一个有关现在集成电路效率的实验,发现在Python这样的人们经常能接触到的高级语言上运行矩阵乘法,性能是1的话,用C语言重写后,性能可以提升到50。如果充分挖掘整个处理器微架构的内容,比如循环并行化、访存优化,使用SIMD等,性能可以提升到最高63000。这意味着,随着微架构越来越复杂,人们在应用端出了很多问题,很难使用如此复杂和有深度的微架构的全部资源。
在这种情况下,人们开始使用定制的硬件来执行那些经常使用,又对性能影响很大的计算,这就是我们多次提到的DSA。通用架构和领域内专属微架构的差别在于,通用架构往往比较庞大,整体效率在计算不同类型操作的时候,相对来说以高效率且可完成不同类型的任务和计算为目的。而DSA则不考虑非领域内的其他操作,整体设计以提高领域内某项专属计算的效率为主。这就造成了DSA硬件相对通用计算硬件几十倍乃至上万倍的性能提升。
对CPU而言,在超算中加入GPU也是一种类型的DSA化。从设计CPU的角度来说,1个CPU微架构中,用于真正计算的ALU、FPU等单元所占用的晶体管数量是非常少的,大部分晶体管都用于逻辑处理、缓存等部分。因此,CPU在计算能力方面,如果增加CPU数量的话,增加的更多是缓存和逻辑控制部分,实际的计算部分增加并非很多。因此,在这种情况下,人们使用计算部分较多、但是逻辑部分较弱的GPU加入其中,对大量并行的数据进行处理,就获得了非常不错的加速效能。
其次是牧本定律,它认为半导体产品的发展,总是在标准化和定制化之间左右摇摆,大概每隔10年波动一次。牧本定律的背后,则是性能、功耗和开发效率之间的平衡。
更具体一些来说的话,对于性能功耗比和开发效率,是两个难以同时满足的目标,性能功耗比高的产品,其开发效率一定不高,毕竟它的架构更偏向于专用。反过来,对通用效率很高的架构来说,性能功耗比肯定表现远不如专一架构那么高,毕竟有大量的逻辑部分、多余的计算部分需要支撑非特定计算外的通用计算。因此,对大部分厂商而言,是不断地在性能功耗和开发效率之间摇摆,随着工艺水平增加,性能功耗提升,通用处理器的性能会得到大幅度提高,但是在工艺水平维持的阶段,专用处理器由于其极高的能耗比又会得到厂商和业内的青睐。
从目前的发展情况来看,厂商会选择尽可能在满足通用性的情况下,加强整个系统的专用计算效能。比如英特尔和AMD选择将CPU和GPU利用Chiplet技术制作在一张硅片上,以实现更高的性能功耗比,尤其针对AI计算等新型应用。对超级计算机而言,同样的趋势也正在发生,目前超算也在逐渐摆动至向DSA化发展的过程中。
在大趋势的指引下,无论是英特尔、英伟达还是AMD,都在不断努力尝试,无论是一个整体的芯片或采用Chiplet链接多个芯片,这些厂商都在通过不断加入更多的DSA化定制模块的方式来提高处理器的效能或性能。具体到产品上,英伟达为GPU的传统CUDA流处理器模块之外,又加入了张量核心模块,此外还推出了专门的训练计算卡以及DPU这类专用的数据处理芯片。英特尔甚至开始为全新的第四代至强可扩展系列处理器增加专用的DSA,比如面向5G计算、面向加解和面向解压缩等不同场合的DSA模块,并且通过不同的搭配和数量配置,向拥有不同需求的企业收费,开创了x86处理器收费运营的新模式。

英特尔全新的第四代至强可扩展处理带来了大量的加速单元
最后是贝尔定律。贝尔定律是指每隔10年,就会出现新一类的计算机(或者编程平台、新的网络连接、新的用户接口等),形成新的产业。无论是DPU、XPU的诞生,还是AIoT时代的到来,都彰显着这种趋势。未来的计算将面对集成了不同的传感器、不同的加速器的碎片化需求,因此不同领域和不同需求的行业,对芯片的需求是不同的。因此就有了英特尔对企业的定制化配置,以及AMD针对不同应用需求开发不同的架构比如RDNA和CDNA,去配合不同的CPU和GPU搭配、总线和缓存搭配等。
变化正在发生
超算市场的DSA化发展是当前最显著的一个变化趋势,厂商在不断加强CPU、GPU之间互联的性能,同时通过对编程模型和硬件统一内存架构方面的优化与加强等方式,不断增强整个系统的性能。此外,在CPU或者GPU的模块内部,整个系统还在不断地通过增加特色加速模块的方式提高那些常见且所需算力巨大的计算模式的效率。实际上我们也看到,随着DSA模块的加入,的确大幅度提升了超算实际应用的性能,在目前的工艺和应用条件下,多芯并举的趋势还将继续发展下去,直到下一次变革的到来。

0 留言