



全文链接:http://tecdat.cn/?p=31958
分析师:Yan Liu
目前对于二手房交易价格的预测主要考虑的是房屋价格受宏观因素的影响,如国家政策、经济发展水平、人口数量等,并据此推测地区房价及其走势,很少有从微观的角度来准确预测每间房屋的价格。
相关视频
解决方案
任务/目标
从区位特征、房屋属性和交易指标3个角度,选取包括所属区域、建筑面积、楼层高度、周边银行数量、学校数量、电影院数量等在内的多维度特征,帮助客户来预测二手房的挂牌价格,实现基于数据的科学决策,做到一房一价的精准预测。
数据 获取
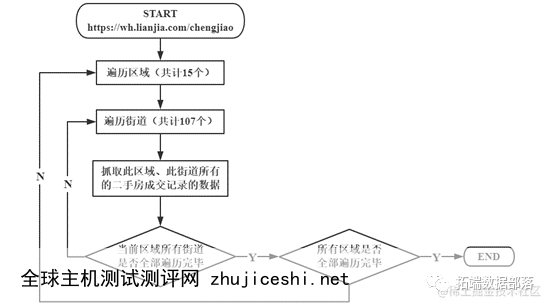
(1)在链家网上,武汉市区域被划分为15个区,共107个街道,每个页面展示30条房屋数据,通过翻页最多可以达到100页,即3000条数据。为了能尽可能保证抓取到链家上所有的数据(查看文末了解爬虫代码免费获取方式),根据深度优先算法思想,采用先遍历区域,再遍历街道的遍历思路来设计爬虫。
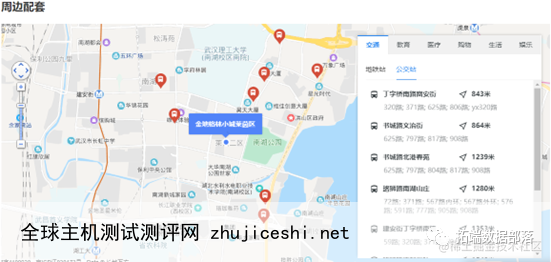
(2)周边配套设施,房屋所在小区的经纬度数据可以从网页源代码中获得,其关键词为:resblockPosition。通过调用百度地图API可以获得上图所示的周边配套设施数量,涵盖了交通、教育、医疗、购物、生活、文娱共6大类,19个特征变量。
特征 预处理
(1)缺失值处理
通过对数据缺失值统计发现有8个变量存在缺失值:
分别使用剔除法、填充法来处理缺失值。houseStructure共有四种类型:平层、复式、错层、跃层。考虑到位于同一小区的房屋,其房屋类型大多相同,故采用此方法对缺失值进行填充:对于缺失houseStructure的房屋A,根据community_id(所属小区ID)统计出与A同小区的所有房屋,再统计出这些房屋的houseStructure的众数对A进行填充。buildingTypes、liftEquip和premisesOwnership采用和houseStructure同样的填充方法。propertyFee数据的缺失选择使用均值填充法。
分类变量的处理
对于分布极不均衡的分类变量予以剔除,对于其他分类变量做硬编码或独热编码处理
数值变量的处理
buildingTime:建成年代,数据格式均为年份(如:2018),处理方法为构造新的变量YearsDelta,其值等于2020年与其差值。
通过三σ法则剔除异常值。周边配套设施包含了一公里内的地铁站数量、幼儿园数量、医院数量等19个数值变量,通过绘制分布直方图发现不少变量的分布存在偏态。
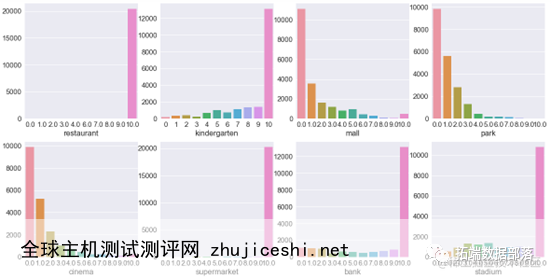
分别予以剔除或是将数值变量转换为二分类变量。
数据变换
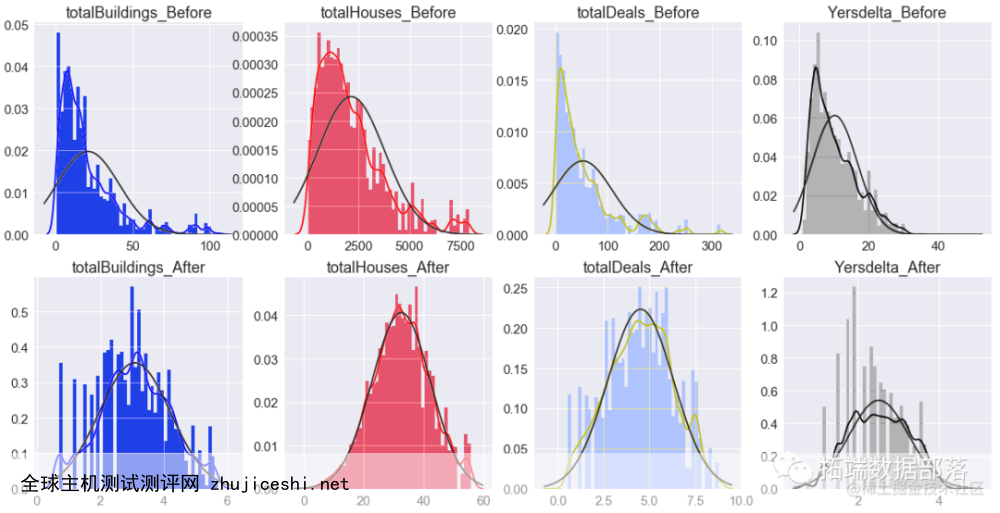
通过绘制变量分布图,发现totalBuildings、totalHouses、totalDeals和Yearsdelta呈现出较为明显的右偏分布,而呈现偏态分布的数据是不利于最终所构建模型的效果的,因此需要对这几个变量进行纠偏处理,采用的方法为Johnson变换。
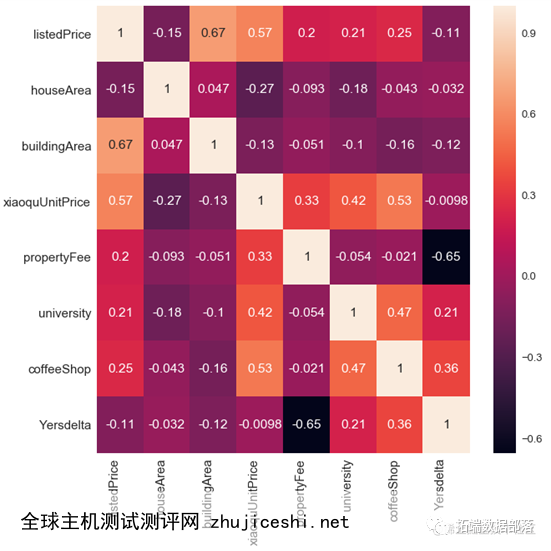
上述变量经过此方法处理前后分布对比图如下,显然,经过处理后的变量分布已近似于正态分布。

0 留言