



原标题:一次 MySQL 误操作导致的事故,“高可用”都顶不住了!
你好,我是悟空。
上次我们项目不是把 MySQL 高可用部署好了么,MySQL 双主模式 + Keepalived,来保证高可用。简单来说就是有两个 MySQL 主节点,分别有两个 Keepalived 安装在宿主机上监控 MySQL 的状态,一旦发现有问题,就重启 MySQL,而客户端也会自动连接到另外一台 MySQL。
这次是我们在项目中遇到的一次事故,来一起复盘下吧。
本文目录如下:
事故现场
环境:测试环境
时间:上午10:30
反馈人员:测试群,炸锅了,研发同事初步排查后,发现可能是数据库问题。
然后就开始找原因吧。因为这套集群环境是我部署的,所以我来排查的话轻车熟路。
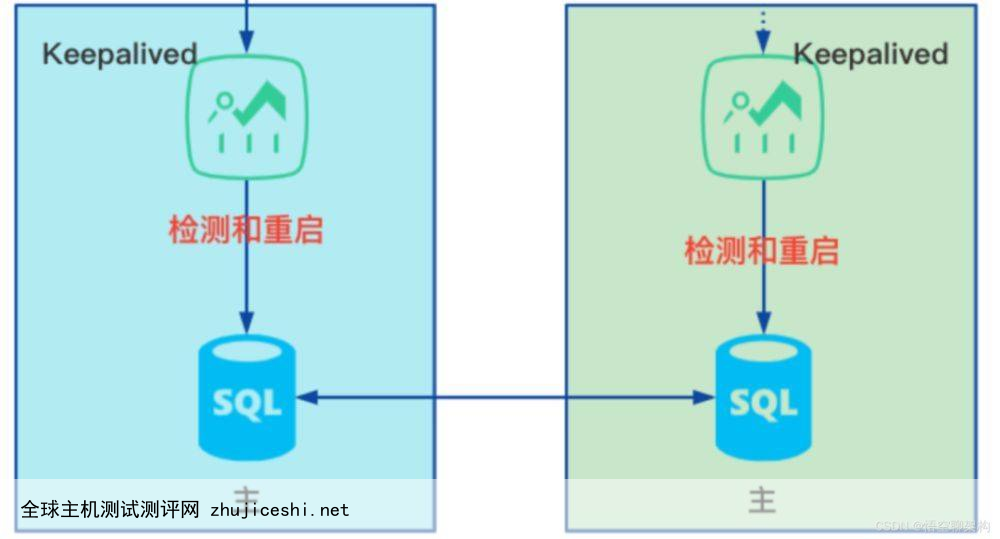
系统部署图
先说下系统的部署图,方便大家理解。
两个数据库部署在 node55 和 node56 节点上,他们互为主从关系,所以叫做双主。
还有两个 Keepalived 部署在 node55 和 node56 上面,分别监控 MySQL 容器的状态。
报错原因和解决方案
① 我第一个想法就是,不是有 Keepalived 来保证高可用么,即使 MySQL 挂了,也可以通过 Keepalived 来自动重启才对。即使一台重启不起来,还有另外一台可以用的吧?
② 那就到服务器上看下 MySQL 容器的状态吧。到 MySQL 的两台服务器上,先看下 MySQL 容器的状态,docker ps 命令,发现两台 MySQL 容器都不在列表中,这代表容器没正常运行。
③ 这不可能,我可是安装了 Keepalived 高可用组件的,难道 Keepalived 也挂了?
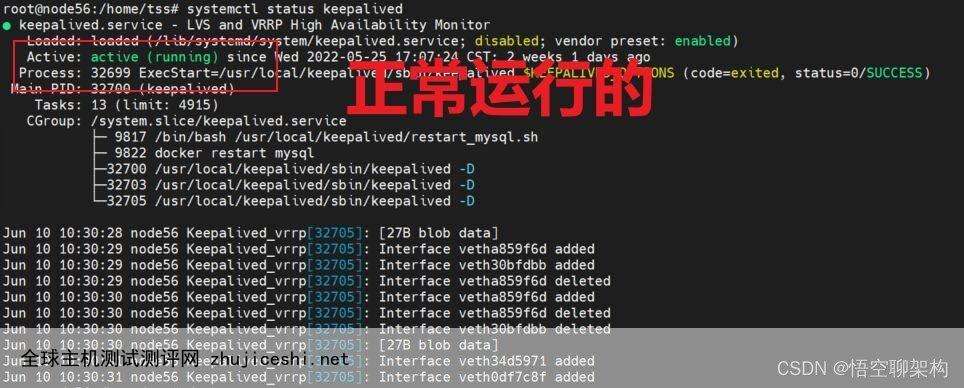
④ 赶紧检查一波 Keepalived,发现两台 Keepalived 是正常运行的。通过执行命令查看:systemctl status keepalived
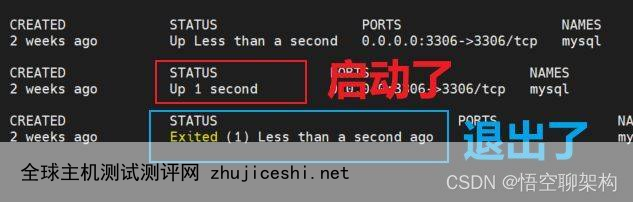
⑤ 纳尼,Keepalived 也是正常的, Keepalived 每隔几秒会重启 MySQL,可能我在那一小段空闲时间没看到 MySQL 容器启动?换个命令执行下,docker ps -a,列出所有容器的状态。可以看到 MySQL 启动后又退出了,说明 MySQL 确实是在重启。
⑥ 那说明 Keepalived 虽然重启了 MySQL 容器,但是 MySQL 自身有问题,那 Keepalived 的高可用也没办法了。
⑦ 那怎么整?只能看下 MySQL 报什么错了。执行查看容器日志的命令。docker logs
。找到最近发生的日志:
⑧ 提示 mysql-bin.index 文件不存在,这个文件是配置在主从同步那里的,在 my.cnf 配置里面。

这个配置好后,然后执行主从同步的时候,就会在 var/lib/mysql/log 目录下生成多个 的文件。还有一个 索引文件,它会标记现在 日志文件记录到哪里了。
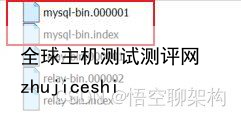
文件里面的内容如下:
这个 文件还是带序号的,这里还有坑,后面我再说。
⑨ 报错信息是提示缺少 mysql-bin.index,那我们就去检查下呗,确实没有啊!先不管这个文件怎么消失的吧,赶紧把这个 log 文件夹先创建出来,然后 mysql 会自动给我们生成这个文件的。
解决方案:执行以下命令创建文件夹和添加权限。
⑩ 两台服务器上都有这个 log 目录后,Keepalived 也帮我们自动重启好了 MySQL 容器,再来访问下其中一个节点 node56 的 MySQL 的状态,咦,居然报错了。
可以看到几个关键信息:
Slave_IO_Running: NO,当前同步的 I/O 线程没有运行,这个 I/O 线程是从库的,它会去请求主库的 binlog,并将得到的 binlog 写到本地的 relay-log (中继日志)文件中。没有运行,则代表从库同步是没有正常运行。
Master_Log_File: mysql-bin.000014,说明当前同步的日志文件为 ,之前我们看到节点 node56 上 mysql.index 里面写的是 000001,这个 000014 根本就不在 index 文件里面,所以就会报错了。
这里涉及到主从同步的原理,上一张图:
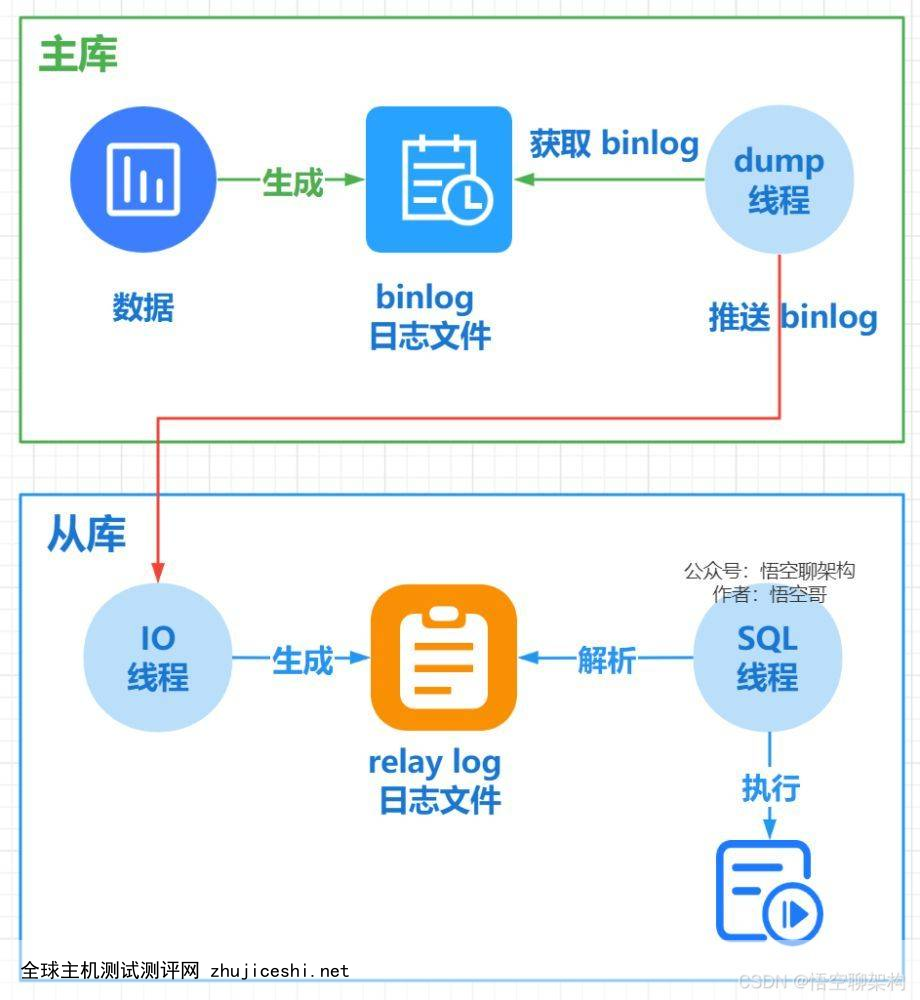
从库会生成两个线程,一个 I/O 线程,一个 SQL 线程;
I/O线程会去请求主库的 binlog 日志文件,并将得到的 binlog 日志文件 写到本地的 relay-log (中继日志)文件中;
主库会生成一个 dump 线程,用来给从库 I/O 线程传 binlog;
SQL线程,会读取 relay log 文件中的日志,并解析成 SQL 语句逐一执行。
那好办啊,我们重新指定下同步哪个日志文件,以及同步的位置就好了。
解决方案:
看下主库 node55 上日志文件状态。
记下这两个信息:File=mysql-bin.00001,Position=117748。(这里也有个坑:先要锁表,再看这两个值,从库开始同步后,再解锁表)。
具体执行的命令如下:
然后在从库 node56 上重新指定同步的日志文件和位置:
再次查看就不报错了,I/O 线程也跑起来了,
在这里插入图片描述
然后将 node55 当做从库,node56 当做主库,同样执行上面的几步,状态显示正常了,然后用 navicat 工具连下数据库,都是正常的,在测试群反馈下结果,搞定收工。
好像忘了一个问题,为啥 log 文件夹被干掉了??
为什么会出现问题?
然后问了一波当时有没有人删除这个 /var/lib/mysql/log 目录,也没有人会随便删除这个目录的吧。
但是发现 log 的上级目录 /var/lib/mysql 有很多其他文件夹,比如 xxcloud, xxcenter 等。这不就是我们项目中几个数据库的名字么,只要在这个目录的文件夹,都会显示在 navicat 上,是一一对应的,如下图所示。其中也显示了 log 数据库。

那会不会有人从 navicat 上干掉了 log 数据库?极有可能啊!
果然,有位同事之前在迁移升级的过程中,发现这个 log 数据库在老的系统是没有的,所以就清理了,这就相当于把 log 数据库干掉了,同时也会把 log 文件夹干掉了。好了,终于水落石出了!这个其实也是我前期没有考虑到 log 目录的一个问题。没错,这是我的锅~
改进
其实操作同步数据库的时候,不应该用这种覆盖同步的方式,可以采取单库同步的方式,也就不会干掉 log 数据库了。但是,这个 log 数据库放在这里有点奇怪啊,能不能不要出现在这里呢?
我们只要指定这个 log 目录不在 /var/lib/mysql 目录下就好了。
东哥建议:log 文件和数据库 data 文件进行隔离:
datadir = /var/lib/mysql/data
log_bin = /var/lib/mysql/log
另外一个问题,我们的高可用真的高可用了吗?
至少没有做到及时报警,MySQL 数据库挂了,我是不知道的,都是通过测试同学反馈的。
能不能及时感知到 MySQL 异常呢?
这里可以利用 Keepalived 发送邮件的功能,或者通过日志报警系统。这个是后面需要改进的地方。返回搜狐,查看更多
责任编辑:

0 留言