



首先在zabbix_agent下定义一个获取磁盘IO信息的脚本:
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/disk_status.sh
#/bin/sh
Device=$1
DISK=$2
case $DISK in
rrqm)
iostat -dxkt 1 2|grep "\b$Device\b"|tail -1|awk {print $2}
;;
wrqm)
iostat -dxkt 1 2|grep "\b$Device\b"|tail -1|awk {print $3}
;;
rps)
iostat -dxkt 1 2|grep "\b$Device\b"|tail -1|awk {print $4}
;;
wps)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $5}
;;
rKBps)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $6}
;;
wKBps)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $7}
;;
avgrq-sz)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $8}
;;
avgqu-sz)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $9}
;;
await)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $10}
;;
svctm)
iostat -dxkt 1 2|grep "\b$Device\b" |tail -1|awk {print $11}
;;
util)
iostat -dxkt |grep "\b$Device\b" |tail -1|awk {print $12}
;;
esac
配置介绍:
rrqm/s: 每秒进行merge的读操作数目,即rmerge/s
wrqm/s: 每秒进行merge的写操作数目,即wmerge/s
r/s: 每秒完成的读IO设备次数, rio/s
w/s: 每秒完成的写IO设备次数, wio/s
rkB/s: 每秒读K字节数,KB/s
wkB/s: 每秒写K字节数,KB/s
avgrq-sz:平均每次设备IO操作的数据大小
avgqu-sz: 平均每次设备IO队列长度
Await: 平均每次设备IO操作的等待时间,ms
Svctm: 平均每次设备IO操作的服务时间,ms
%util:一秒中有百分之多少的时间用于 I/O,即被消耗的CPU百分比
如果%util接近100%,说明产生的I/O请求太多,I/O系统已经满负荷
idle小于70% IO压力就较大了,一般读取速度有较多的wait。
定义一个获取磁盘磁盘名字的脚本:
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/disk_discovery.sh
#!/bin/bash
diskarray=(`cat /proc/diskstats |grep -E "\bsd[a-z]\b|\bxvd[a-z]\b|\bvd[a-z]\b"|awk {print $3}|sort|uniq 2>/dev/null`)
length=${#diskarray[@]}
printf "{\n"
printf \t"\"data\":["
for ((i=0;i<$length;i++))
do
printf \n\t\t{
printf "\"{#DISK_NAME}\":\"${diskarray[$i]}\"}"
if [ $i -lt $[$length-1] ];then
printf ,
fi
done
printf "\n\t]\n"
printf "}\n"
添加userparameter配置文件:
vim /usr/local/zabbix/etc/zabbix_agentd.conf.d/disk_status.conf
UnsafeUserParameters=1
UserParameter=disk.discovery[*],/usr/local/zabbix/etc/zabbix_agentd.conf.d/disk_discovery.sh
UserParameter=disk.status[*],/usr/local/zabbix/etc/zabbix_agentd.conf.d/disk_status.sh $1 $2
zabbix_agentd.conf 添加 配置文件
Include=/usr/local/zabbix/etc/zabbix_agentd.conf.d/*.conf
Zabbix web界面创建模
创建自动发现规则

创建自动发现规则

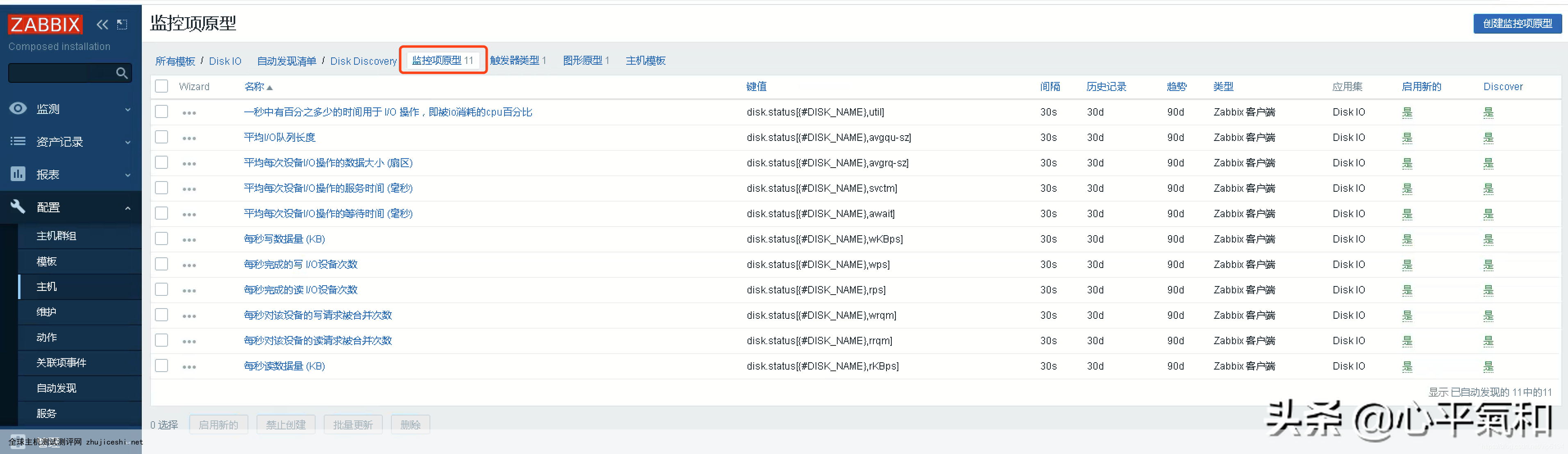
创建监控项原型
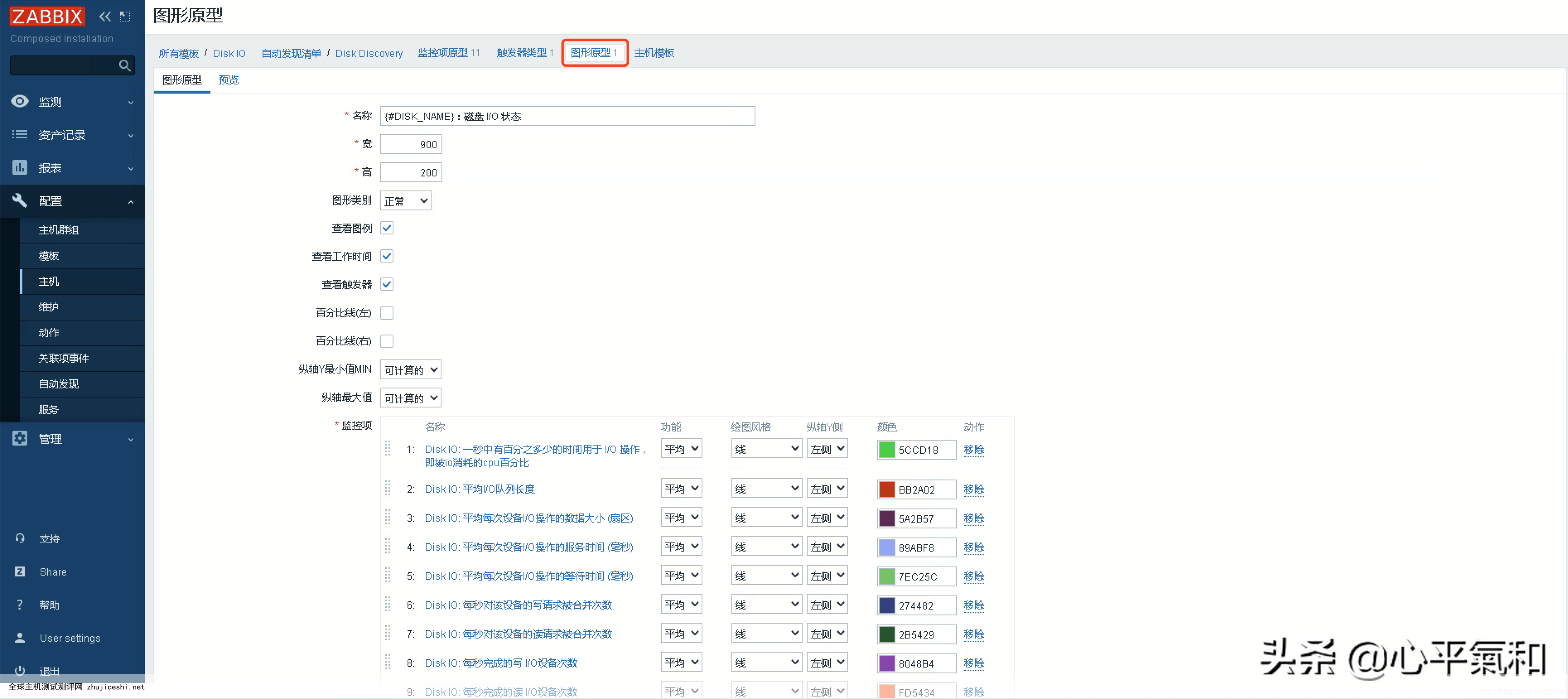
创建图形原型,再将刚刚创建的监控项原型添加到图形原型中
最后再将模板链接至主机
查看图形
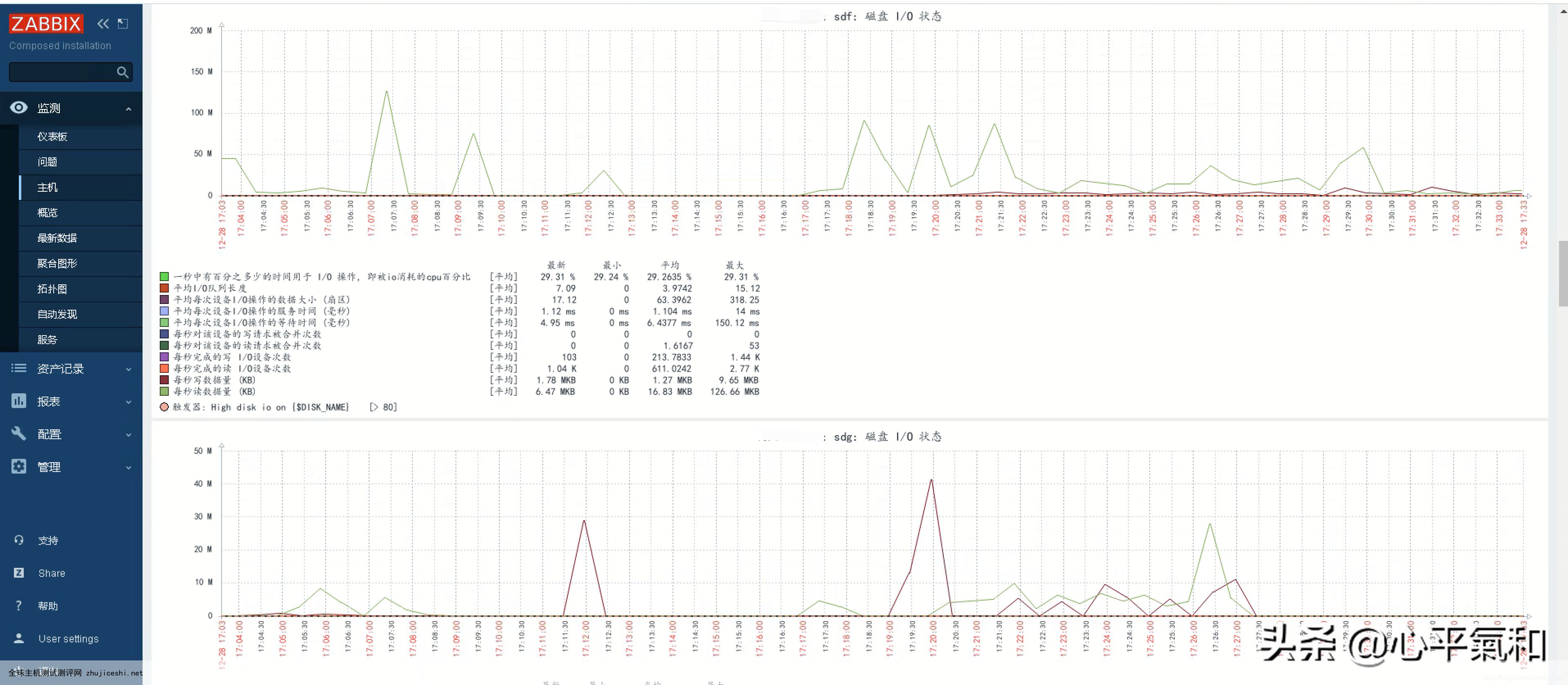
iostat ,将对系统的磁盘操作活动进行监视
1、%iowait<20 为好,=35为坏,>=50为糟糕,如果%iowait的值过高,表示硬盘存在I/O瓶颈。(%iowait:CPU等待输入输出完成时间的百分比)
2、若%idle值高,表示CPU较空闲,如果%idle值高但系统响应慢时,有可能是CPU等待分配内 存,此时应加大内存容量。%idle值如果持续低于10,那么系统的CPU处理能力相对较低,表明系统中最需要解决的资源是CPU。(%idle:CPU空闲时间百分比)
3、命令:iostat -d -x -k 1 1
4、如果 %util 接近 100%,说明产生的I/O请求太多,I/O系统已经满负荷,该磁盘可能存在瓶颈。(%util: 一秒中有百分之多少的时间用于 I/O 操作,即被io消耗的cpu百分比)%idle小于70% IO压力就较大了,一般读取速度有较多的wait。
5、可以结合vmstat 查看查看b参数(等待资源的进程数)和wa参数(IO等待所占用的CPU时间的百分比,高过30%时IO压力高)。
6、avgqu-sz 也是个做 IO 调优时需要注意的地方,这个就是直接每次操作的数据的大小,如果次数多,但数据拿的小的话,其实 IO 也会很小。如 果数据拿的大,才IO 的数据会高。也可以通过 avgqu-sz × ( r/s or w/s ) = rsec/s or wsec/s。也就是 讲,读定速度是这个来决定的。(avgqu-sz: 平均I/O队列长度。)、(r/s: 每秒完成的读 I/O 设备次数。即 rio/s)、(w/s: 每秒完成的写 I/O 设备次数。即 wio/s)
7、如果 svctm 比较接 近 await,说明 I/O 几乎没有等待时间;如果 await 远大于 svctm,说明I/O 队列太长,io响应太慢,则需要进行必要优化。如 果avgqu-sz比较大,也表示有大量io在等待。
其中的svctm一项,反应了磁盘的负载情况,如果该项大于15ms,并且util%接近100%,那就说明,磁盘现在是整个系统性能的瓶颈
await: 平均每次设备I/O操作的等待时间 (毫秒)。
svctm: 平均每次设备I/O操作的服务时间 (毫秒)。
脚本下载:需要的联系我
————————————————

0 留言