



近年来,随着AI应用的快速发展,引发一场算力革命,异构计算也站在风口浪尖。
异构计算主要是指使用不同类型指令集和体系架构的计算单元组成系统的计算方式。常见的计算单元类别包括CPU、GPU、DSP、ASIC、FPGA等。目前“CPU+GPU”以及“CPU+FPGA”都是受业界关注的异构计算平台。
近日,英特尔宣布将在未来一年半内取消多款服务器GPU产品的发布计划,其中包括HPC级的Rialto Bridge GPU,以全力开发基于Falcon Shores的混合芯片。英特尔新一代Falcon Shores 专为超级计算应用而设计,将CPU和GPU技术结合到一个芯片封装中,届时将作为纯GPU架构面世。
值得注意的是,AMD 的Instinct MI300和英伟达的Grace Hopper超级芯片也是采用“CPU+GPU”的异构形式。
01
CPU与GPU的区别
CPU即中央处理器(Central Processing Unit),作为计算机系统的运算和控制核心,主要负责多任务管理、调度,具有很强的通用性,是计算机的核心领导部件,好比人的大脑。不过其计算能力并不强,更擅长逻辑控制。
GPU即图形处理器(Graphics Processing Unit),采用数量众多的计算单元和超长的流水线,擅长进行图像处理、并行计算。对于复杂的单个计算任务来说,CPU 的执行效率更高,通用性更强;对于图形图像这种矩阵式多像素点的简单计算,更适合用 GPU 来处理。AI 领域中用于图像识别的深度学习、用于决策和推理的机器学习以及超级计算都需要大规模的并行计算,因此更适合采用 GPU 架构。
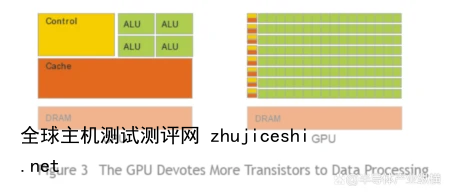
多核 CPU 与 GPU 的计算网格(图中绿色方格为计算单元)
CPU和GPU还有一个很大的区别就是:CPU可单独作用,处理复杂的逻辑运算和不同的数据类型,但当需要处理大量类型统一的数据时,则可调用GPU进行并行计算。但GPU无法单独工作,必须由CPU进行控制调用才能工作。
02
CPU+GPU架构的优势及应用
当CPU和GPU协同工作时,因为 CPU 包含几个专为串行处理而优化的核心,而 GPU 则由数以千计更小、更节能的核心组成,这些核心专为提供强劲的并行运算性能而设计。程序的串行部分在 CPU 上运行,而并行部分则在 GPU上运行。GPU 已经发展到成熟阶段,可轻松执行现实生活中的各种应用程序,而且程序运行速度已远远超过使用多核系统时的情形。因此,CPU和GPU的结合刚好可以解决深度学习模型训练在CPU上耗时长的问题,提升深度学习模型的训练效率。
随着CPU与GPU的结合,其相较于单独CPU与GPU的应用场景也不断拓宽。
第一,CPU+GPU架构适用于处理高性能计算。伴随着高性能计算类应用的发展,驱动算力需求不断攀升,但目前单一计算类型和架构的处理器已经无法处理更复杂、更多样的数据。数据中心如何在增强算力和性能的同时,具备应对多类型任务的处理能力,成为全球性的技术难题。CPU+GPU的异构并行计算架构作为高性能计算的一种主流解决方案,受到广泛关注。
第二,CPU+GPU架构适用于处理数据中心产生的海量数据。数据爆炸时代来临,使用单一架构来处理数据的时代已经过去。比如:个人互联网用户每天产生约1GB数据,智能汽车每天约50GB,智能医院每天约3TB数据,智慧城市每天约50PB数据。数据的数量和多样性以及数据处理的地点、时间和方式也在迅速变化。无论工作任务是在边缘还是在云中,不管是人工智能工作任务还是存储工作任务,都需要有正确的架构和软件来充分利用这些特点。
第三,CPU+GPU架构可以共享内存空间,消除冗余内存副本来改善问题。在此前的技术中,虽然GPU和CPU已整合到同一个芯片上,但是芯片在运算时要定位内存的位置仍然得经过繁杂的步骤,这是因为CPU和GPU的内存池仍然是独立运作。为了解决两者内存池独立的运算问题,当CPU程式需要在GPU上进行部分运算时,CPU都必须从CPU的内存上复制所有的资料到GPU的内存上,而当GPU上的运算完成时,这些资料还得再复制回到CPU内存上。然而,将CPU与GPU放入同一架构,就能够消除冗余内存副本来改善问题,处理器不再需要将数据复制到自己的专用内存池来访问/更改该数据。统一内存池还意味着不需要第二个内存芯片池,即连接到CPU的DRAM。
因此,通过CPU+GPU异构并行计算架构组成的服务器,正成为服务器市场中的一匹黑马。现在已有多家芯片厂商开始跟进。
03
芯片巨头的香饽饽?
英特尔的Falcon Shores
英特尔的Falcon Shores XPU专为超级计算应用而设计,其将CPU和GPU合并到一个混合匹配芯片包中。Falcon Shores代表了英特尔异构架构设计的延续,其最终目标是每瓦性能提高5倍,x86插槽计算密度提高5倍以及现有服务器芯片的内存容量和带宽提高5倍。英特尔的高性能计算CPU和GPU路线图与Falcon Shores汇合,表明这些芯片将在未来同时发挥这两个作用。
英特尔超级计算集团副总裁兼总经理杰夫麦克维(Jeff McVeigh)说,延迟推出的Falcon Shores将在2025年首次推出GPU内核,但尚未表明何时将CPU内核集成到设计中。因此,英特尔以HPC为中心的设计将落后于竞争对手数年。
英伟达的Grace Hopper超级芯片
2021年,英伟达推出解决HPC和大规模人工智能应用程序的Grace Hopper超级芯片。这是一款完全专为大规模 AI 和高性能计算应用打造的突破性加速 CPU。它通过英伟达 NVLink-C2C 技术将 Grace 和 Hopper 架构相结合,为加速 AI 和 HPC 应用提供 CPU+GPU 相结合的一致内存模型。
英伟达官方表示,使用NVLink-C2C互连,Grace CPU将数据传输到Hopper GPU的速度比传统CPU快15倍。另外,采用CPU+GPU的Grace Hopper核心数减半,LPDDR5X内存也只有512GB,但多了显卡的80GB HBM3内存,总带宽可达3.5TB/s,代价是功耗1000W,每个机架容纳42个节点。
英伟达Grace Hopper超级芯片计划于2023年上半年推出。
AMD的 Instinct MI300
在近日的 CES 2023展会上,AMD 披露了面向下一代数据中心的 APU 加速卡产品 Instinct MI300。这颗芯片采用多芯片、多IP整合封装设计,5nm先进制造工艺,晶体管数量多达1460亿个。它同时集成CDNA3架构的GPU单元(具体核心数量未公开)、Zen4架构的24个CPU核心、大容量的Infinity Cache无限缓存,还有8192-bit位宽、128GB容量的HBM3高带宽内存。
在技术方面,MI300支持第四代Infinity Fabric总线、CXL 3.0总线、统一内存架构、新的数学计算格式,号称AI性能比上代提升多达8倍,可满足百亿亿次计算需求。
AMD CEO苏姿丰近日确认,Instinct MI300将在今年下半年正式推出。
英特尔的Falcon Shores XPU是与英伟达的Grace Hopper 超级芯片和AMD Instinct MI300数据中心APU竞争的关键。英伟达的Grace和AMD的MI300都将于今年推出。值得注意的是,三家均选择了Chiplet技术。
04
未来押注超异构计算
关于异构计算,英特尔中国研究院院长宋继强曾表示:“在2023年,大家已经完全接受了要通过异构计算解决未来系统的设计和优化问题。在2020年的时候,市场还在讨论异构集成是怎么一回事。而在2023年,大家都会基于功能的有效性、设计的难易程度、成本等方面的考量,自觉采用异构计算的方式。”
关于对当下的算力演进方向的新判断,宋继强还提到:“传统异构计算并不能满足现在计算的要求。而“超异构计算”,已逐渐成为业界思考的一个趋势”。
从实际来看,英特尔也确实正在押注“超异构计算”这条道路。
英特尔提出的“超异构计算”概念,在一定程度上可以理解为通过封装技术所实现的模块级系统集成,即通过先进封装技术将多个Chiplet装配到一个封装模块当中,既简化了SOC的复杂技术,更加灵活,又避免了PCB板级集成的性能和功耗瓶颈。
英特尔的“超异构计算”路线以“Foveros”3D封装技术为基础。相比SiP只能实现逻辑芯片与内存的集成,“Foveros”可以在逻辑芯片与逻辑芯片之间实现真正的三维集成,使得芯片面积更小,同时保证芯片间的带宽更大、速度更快、功耗更低。
不过,英特尔的“超异构计算”的创新之处并不仅局限于3D封装这一个层面。事实上,在制程、架构、内存、互连、安全、软件等多个层面均具有领先优势。“超异构计算”的实现是建立在整合其多层面技术优势基础上的。
除了英特尔之外,英伟达也已经在执行层面全面行动。英伟达在云、网、边、端等复杂计算场景,基本上都有重量级的产品和非常清晰的迭代路线图。

0 留言