



【文/观察者网 周毅 吕栋】
虽然OpenAI在前一天发布GPT-4抢走了不少热度、带来一些压力,但百度并未改变原计划,在上周四如期推出了大型语言模型、生成式AI产品“文心一言”。
把时间拨回到发布会召开那一刻。
当文心一言顶着“国内第一个”的光环亮相后,百度CEO李彦宏坦承,文心一言对标ChatGPT甚至是GPT-4,门槛还是很高的,“我自己测试感觉还是有很多不完美的地方”。
或许是这样的表态,以及李彦宏在现场用录屏展示的操作,影响了资本市场的信心。在发布会最关键的时刻,百度股价却出现短线急跌。
但随着“文心一言”逐步放开体验,以及百度对外释放“申请测试企业破9万”等信息,资本市场的态度开始分化甚至反转。
上周五,百度股价大涨14%。随着新的一周到来,百度股价今天(3月20日)延续涨势,早盘高开3%,收盘涨幅收窄至1%左右,相关概念股也随之拉升。

百度股价走势
在发布会上,“文心一言”展示了文学创作等五方面功能。但由于现场是视频演示,被部分网友调侃为“ChatPPT”。
在真实场景中,文心一言的水平到底如何?实力能否对标ChatGPT?观察者网在拿到测试资格后,也对文心一言进行了一番实测。
先总结下结论,正如李彦宏所说,文心一言的表现确实“算不上完美”、“进步空间很大”,甚至有时候还会胡说八道,但强如GPT-4也不能完全避免这些问题。
从实测来看,文心一言的表现没有想象中的那么差,甚至在部分场景中有些出人意料。随着公测逐步放开,反馈越来越多,文心一言这类大模型的水平可能会进一步提高。

文心一言生成的图片
实测“五大功能”,部分结果出乎意料
在发布会上,李彦宏相继介绍了文心一言的五个功能:文学创作、商业文案创作、数理逻辑推算、中文理解、多模态生成。
利用这五个功能,文心一言帮刘慈欣续写了《三体》,介绍了洛阳纸贵背后的经济学原理,计算了鸡兔同笼数学题,并根据指令生成了海报和一段宣传视频。
在真实场景中,文心一言的水平如何?观察者网也一一测试了这五个功能。
首先是文学创作。
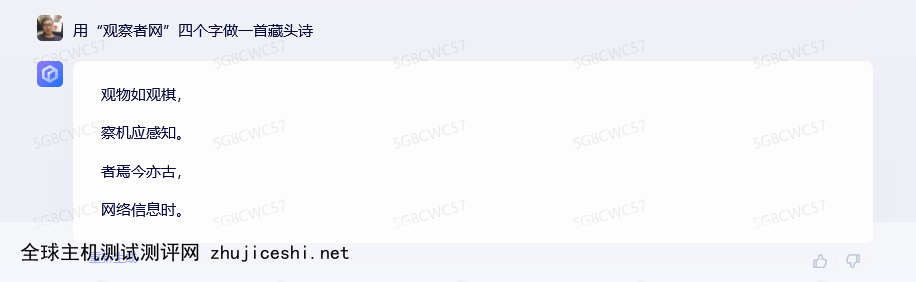
在接收到“用观察者网四个字做一首藏头诗”的指令后,文心一言输出的结果如下:
从结果来看,文心一言理解了藏头诗的指令,但内容乏善可陈,算不上优秀,只能说是以诗歌的格式输出了几句话,而且其中一句并不符合指令的要求。
当把“观察者网”四个字打了双引号后,输出的结果则改进了不少。
第二个场景是商业文案创作。
在接收到“为观察者网制作一条宣传口号”的指令后,文心一言输出了以下内容:

从结果来看,文心一言的表现可以说有些出人意料。
因为它不仅按指令要求制作了一条口号,而且还解释了口号所蕴含的意义。
更关键的是,它好像还十分了解观察者网的日常工作内容,强调了“观察者网提供的内容不仅仅局限于中国,而是全球范围内的新鲜资讯和独特视角。”
这和观察者网“全球视野,中国关怀”的定位已十分接近。
在商业新闻稿生成方面,文心一言的表现也可圈可点,准确理解了指令要求和人物角色。

第三个场景是数理逻辑推算。
先用小品中的“经典案例”考验一下文心一言。
从测试结果来看,文心一言在简单的数学计算理解上没有问题,但在沟通的连续性上似乎表现的并不好,这在一定程度上影响了对话体验。
再换一个小学生日常会遇到的试题,文心一言很快给出了正确答案。但当被问到解题思路时,文心一言则理解错了题意,并给出了错误的答案。

再换一个类似数学题,文心一言好像又理解错了题意,直接给出了错误的答案(正确答案:鸡有12只,兔有19只)。

可见,在数理逻辑推算方面,文心一言还有很大进步空间。在目前水平下,如果问题表达的不够清晰,文心一言很容易给出错误答案。
第四个场景是中文理解。
其实在前面的场景中,已经在一定程度上体现了文心一言的中文理解能力,这里再用两个例子考验一下它。



在以上几个问题中,文心一言体现了自己的中文语言理解能力。但在另外一些问题上,它则切入了“一本正经胡说八道”的模式。

第五个功能是多模态生成,即输入和输出的内容不限于文字,可以根据文字生成图片、语音或视频,这个功能也是ChatGPT不具有的。
在“文生图”方面,文心一言在简单要求下表现的中规中矩,基本上理解了指令要求。


但在用诗词生成图片方面还有待进步。

文心一言的视频生成能力则因成本较高,现阶段还未对所有用户开放,但它会给出拍摄相关视频的方法,这一点值得肯定。

对比火热的ChatGPT,表现如何?
人们之所以关注文心一言,最主要的原因就是ChatGPT的爆火。作为首个“中国版ChatGPT”,文心一言在与真正的ChatGPT同台竞技时,表现又会如何呢?
由于账号限制等客观原因,观察者网选择了ChatGPT免费版(基于GPT-3.5,没有参与3月14日的GPT-4更新),以及文心一言测试版(版本号为V1.0.0,发版日期为3月14日)。试验中,每款程序的回答结果均选取初次生成的内容,不作反复刷新。
第一组问题,主题为“自我介绍”和“如何看待对方”,观察者网分别询问了两个模型。


不难看出,在本轮实测中,两个语言模型在介绍对方时都显得比较客观。
细微的差别是,ChatGPT更加高调,它不仅介绍了自己可以完成的任务类型,还强调自己“不断学习和进化”,“不仅支持中文,还支持多种语言”,“规模比文心一言大得多,训练数据也更加丰富”等,对于可能更适合文心一言的应用场景,它也进行了描述。
相比之下,“文心一言”则相对谦虚或低调,它表示,“每个模型都有自己的特点和优势,不能简单地评价‘谁更厉害’”。
但要指出的是,ChatGPT训练是基于一个固定的数据库,截止日期是2021年9月,也就是说ChatGPT无法掌握从那以后世界上发生的任何事的信息。
因此,它对文心一言的评价可以说是“一本正经胡说八道”,但这不能算是它的错。
第二组问题与经济和财经相关,要求两个模型对股价波动进行解释,以及对二级市场进行预测。前者需要两款模型对“3月16日文心一言发布后,百度股价盘中大跌”的现象进行说明;后者要求两款模型展望A股后期走势。

对于百度股价的波动,ChatGPT和文心一言都强调,自己只是“人工智能语言模型”,它们也都对可能导致股价波动的原因进行了罗列。
差别在于,ChatGPT使用了“从道理上讲”这样的表述,看上去更“冷淡”一些;而文心一言更主动,强调自己“没有情感和个人喜好”,也不会偏袒任何一方。
值得一提的是,文心一言对金融市场的风险进行了额外的提醒,下一个问题也不例外。
在预测A股走势上,文心一言显得本地化了很多,它主动给出了一般性预测,例如中国宏观经济、政策监管、全球市场走势和产业技术迭代可能带来的影响——遗憾的是,或许因为训练数据等限制,文心一言将“预测A股走势”的时间锚定在了2022年。
ChatGPT的回答,显得有些“放之四海而皆准”,似乎可以套用在任何一个股票市场上。
这里仍要说明一下,ChatGPT并不了解2021年9月之后的任何事。
第三个问题,聚焦在数学逻辑推理上。
以前文的问题为例,“鸡、兔共有脚100只,若将鸡换成兔,兔换成鸡,则共有脚86只,鸡兔各有几只?”
文心一言对题意理解有误,给出了错误答案。
ChatGPT则让人眼前一亮,直接开始列方程解答,这一点似乎比文心一言更加“聪明”。但遗憾地是,虽然方程列对了,但答案仍然是错的。当我们把问题重复一遍后,ChatGPT也出现了理解上的偏差。
当话题转向中国古代诗词领域,两个大模型都“翻车”了。
在被要求鉴赏古诗“停车坐爱枫林晚”(出自唐代诗人杜牧的《山行》)时,ChatGPT率先暴露了一些问题。
ChatGPT,首先弄错了《山行》的作者,将其标注为王之涣;其次,在《山行》的首联和颔联之后,ChatGPT开始了“编造”,第三句“慕容琳娜轻冰脆”并未在现有诗句中觅得,第四句“昨夜星辰昨夜风”来自唐代李商隐;第五到八句的《鹊桥仙》来自宋代秦观。
相较于ChatGPT,文心一言的鉴赏虽然较为简短,但并没有明显事实性错误。
当测试以一种类似开放对话的形式,要求两款程序对“停车坐爱枫林晚”作者的其他诗歌作品进行罗列时,两者都出现了问题。
ChatGPT因为弄错了《山行》的作者,错误地罗列出了《登鹳雀楼》和《凉州词》,还将唐代杜甫的《登岳阳楼》也罗列了出来。
刚刚“侥幸逃过一劫”的文心一言,在第二个问题中很快暴露了隐藏的问题。它将开放对话“这首诗的作者”标记为唐代的杜甫,并提供了杜甫的三首诗歌。对于“停车坐爱枫林晚”的作者问题,文心一言也“翻车”了。
在之前的宣传中,ChatGPT一度以擅长“做题”著称。那么,当ChatGPT和文心一言同时面对中国的高考题目时,二者又会有何种表现?
本次试验以去年北京高考语文作文题目“学习今说”为主题,让ChatGPT和文心一言同时撰写了一篇不少于700字的文章。就初次生成的结果来看,两款程序都展示了一定的逻辑和语言组织能力。
但ChatGPT的回答显得更有“机器味”,它看上似乎仅仅根据“学习”这个主题词就完成了整篇作文,和材料的贴合度不高。
文心一言的回答,就显得切题了很多,类似中学生作文一样,文心一言显示对“学不可以己”这段材料进行了说明,并用它作为引子,展开了全文。
在后续行文中,文心一言更为成熟。它既有论点+论据这样类似高考作文结构的表达,也对一些回答,进行了分层论述,它的内容更加详实和丰富,看上去也比ChatGPT的作文更像“真人”,这也在一定程度上体现了文心一言的中文能力。
从以上实测问题来看,备受吹捧的ChatGPT并不是一个“全能战士”,吸引了诸多眼球的“文心一言”也不能令人完全满意,二者都会出现“一本正经胡说八道”的情况。但它们的表现也都没有想象中的那么差,甚至在部分场景中会让人眼前一亮。
在发布会当天股价暴跌后,市场上对文心一言开始出现更多包容性观点。有业内人士坦言,人工智能及其衍生的AIGC十分重要,无论国内做得如何,都得先有一个产品出来。也有市场观点认为,文心一言不需要碾压ChatGPT,只要能做到超过及格线,就很不错了,毕竟这才是第一代产品。
近日在亚布力论坛第二十三届年会上,百度CEO李彦宏谈及外界对文心一言的评价,表示外界对文心一言的反馈跟他预期差不多,ChatGPT刚出来时的反馈比文心一言还要糟糕。
李彦宏坦言,“文心一言”是一个非常典型的、要靠“反馈”才能不断提升的模型,“这也是我为什么很希望及早地把它给发出来”。
通用人工智能的实现不可能“一蹴而就”,或许经过更多数据的训练和用户的“再教育”,ChatGPT和文心一言这类大模型才会表现的更好。
值得警惕的是,在ChatGPT(基于GPT-3.5)火热的同时,OpenAI已在3月15日发布新的多模态模型GPT-4,并称“这是我们迄今为止功能最强大的模型!”
要想在这一领域不落人后,中国企业必须加大投入力度。
看到以上表现,你会如何评价文心一言?
(题图由文心一言生成)

0 留言