



签完三方,代表老刘的秋招正式结束了。作为一个双非本211硕无实习无项目的普通人,自学大数据开发拿到心仪的offer实属不易。秋招期间在各种网站上收获很多,想回报一下大家,分享出老刘的自学大数据开发的学习路线 。
个人背景
学校:双非本通信工程,211硕电子与通信工程,非科班,无实习(导师不让实习),无项目,一个非常普通但努力的应届生。
奖项:本科期间拿过一些数学建模竞赛的奖(没啥用),硕士期间什么都没有,全在给导师做一些破科研项目。
投递岗位:大数据开发工程师或数据平台工程师或数据仓库工程师或数据研发工程师。
拿到的offer:美团(白菜)、京东(SP)、虾皮(白菜)、华为、shein、荣耀、龙湖...。其实拿到美团意向书后就没怎么找了,没想到美团给了一个白菜,还好之前已经拿了几个心仪的。
最后老刘选择去东莞华为,主要因为家人在广州打工,并且华为的总包还行,所以选择了东莞华为。

大数据开发学习路线
大数据开发的自学可以分为四个部分,每个部分老刘结合亲身经历进行描述。
找个正能量伙伴
自学往往是孤独的,网上资料又良莠不齐,自信心往往会受到打击,需要寻找一个充满正能量的人。老刘关注了一个大佬拓跋阿秀,虽然阿秀是搞C++的,但完全不影响阿秀成为老刘的偶像,学习阿秀的刻苦精神即可。阿秀是一个充满正能量的人,在我低落的时候看阿秀的文章总能立马振奋起来,推荐推荐。
如何刷算法题
在秋招过程中,算法是非常非常重要的,笔试要做算法题(有些公司会出原题),面试几乎每一轮都有算法题考核,如果你面试过程中算法题没做出来但通过了这一轮,你的面评可能也不好,最后你的薪资也会受到很大影响。例如我实验室大佬,拿到字节SSP,快手SSP,腾讯SP,可拼多多给他一个白菜价格,他问为什么工资会这么低,那个人说你的算法题做的不是很好(我同学说那天面试他几乎在梦游)。所以一定要重视算法,并且老刘听说很多公司工作中也有算法考核,千万要重视。
老刘的算法题能力经历了一个从0到力扣周赛平均2个题的水平,虽然力扣周赛一般只能做出前两道,但比起开始一题不会,已经有了很大提高。这里就不推荐买什么书籍了,直接上力扣网先刷剑指offer,刚开始可能一道都不会(老刘开始也是这样,不要慌),直接看精选的题解,直接总结别人的方法,总结完这些题后,就会大致了解数组题一般有什么方法,链表一般有什么方法,树一般有什么方法等。
接下来就可以练习力扣HOT100,现在就可以尝试自己去解,解决不了再看题解。首先花10分钟左右思考怎么解决,有没有思路,在草稿纸上画一画。如果10分钟之后还没有想法,就直接看题解吧,别再坚持了,时间是非常宝贵的,不要因为一个题影响一整天的安排,并且面试过程中面试官也不会花特别多时间等你思考(腾讯面试经典情景:给你多少时间,做完这几个题)。如果你有思路,但是不知道怎么写代码,这种也是正常情况,直接看题解,看看大佬们怎么写,多总结多背,题刷多了就自然而然会了。
刷完这些题,算法题中涉及的数据结构基本都接触到了,自己也能解决一些题目了,但不要认为就不用刷了,你要保证你刷过的题一定能写出来,常见题型都能写出来。如果周末有空,建议参加力扣周赛,多锻炼锻炼。
注意老刘只是普通人,老刘的算法建议也是比较适合普通人,大佬忽略这块即可。
有个小技巧:如果你有某一家的面试,你这几天可以多刷一下这家公司的算法常考题,有可能会遇到原题或类似的题。
计算机网络和操作系统
计算机网络和操作系统几乎是面试必问模块,例如百度面试官几乎都会问从浏览器输入一个URL后执行全过程,这模块绝对不能忽视,老刘刚开始这一块没有准备好,百度提前批面试就挂了,之后猛补这方面的知识点,才慢慢收获意向。
如果你有足够的时间,你可以去看B站上的一些视频,例如:B站哈工大的操作系统,B站清华大学的操作系统,B站韩立刚老师的计算机网络。
如果你没有足够的时间,时间已经来到金8银9了,老刘这里就推荐大佬小林Coding,直接背大佬总结计算机网络和操作系统的知识点,小林Coding YYDS。
其实,老刘就是参考小林Coding的资料,猛补的计算机网络和操作系统,从此老刘乱杀。
Linux相关知识点
这方面老刘面试过程中问过最多的就是select、poll、epoll的区别以及实现,老刘这方面推荐看鸟叔私房菜。
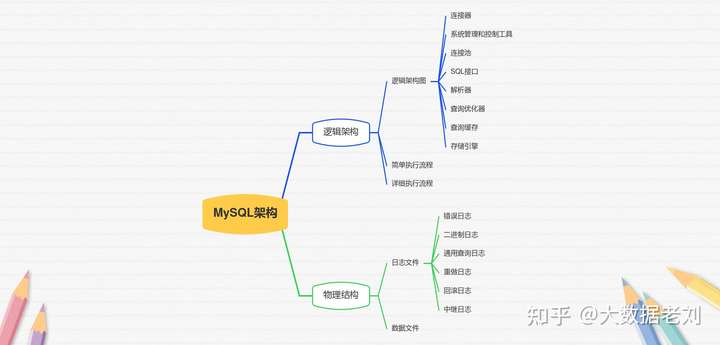
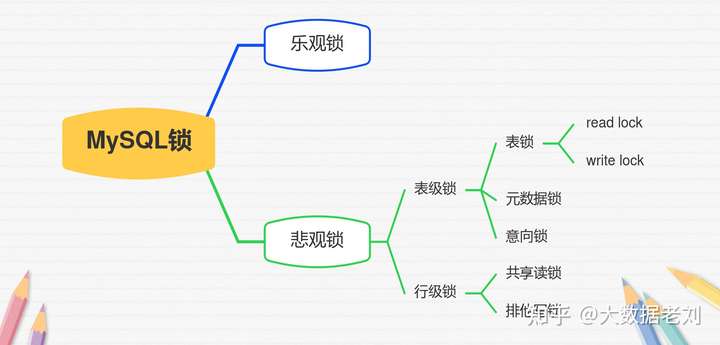
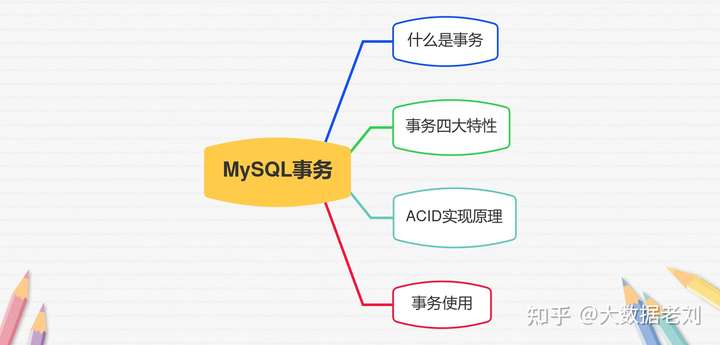
MySQL数据库
MySQL基础操作需要铭记于心,在学完基础操作之后,还要学习MySQL的基础架构、索引、锁、事务。网上MySQL的基础操作资料太多了,老刘就不分享了,老刘分享一些MySQL基础架构、索引、锁、事务的一些知识点。
补充:MySQL最常考的题是MySQL索引为什么要用B+树?

Java基础知识
这块老刘建议大家直接上b站看尚硅谷的java基础视频,老刘怎么讲都没有别的讲的好,专业人干专业事,老刘主要精力放在大数据组件这块。
大数据组件知识点
大数据组件有很多很多,老刘讲述一些学习路线,并不会讲述详细知识点,详细知识点以后在慢慢补充(如有遗漏,请批评指正)。
大数据常见组件包括:HDFS、MapReduce、YARN、Zookeeper、Kafka、Hive、HBase、Flume和Sqoop和Azkaban、Spark、Flink。
分布式存储系统HDFS
- Hadoop是什么?什么是分布式?
- 什么是HDFS?HDFS怎么用?有哪些命令?记住一些基础的就行了,例如查看、创建、上传、下载、修改、删除。
- 数据块的概念
- HDF体系结构
- HDFS心跳机制、负载均衡、安全模式
- HDFS读写流程以及容错机制
- namenode元数据管理
- block设计为128M的原因
- HDFS优点和缺点
- HDFS和SQL区别
- 机架感知以及节点距离计算
- HDFS1.0 2.0 3.0区别
- HDFS小文件的影响
如果还有时间,可以看看HDFS源码,它的启动流程以及HDFS NameNode的双缓冲机制(能够自己写出来)
分布式计算框架MapReduce
- MapReduce是什么?
- 掌握MapReduce最常见的例子:统计一篇文章每个单词出现的总次数
- MapReduce原理、最核心的Shuffle详细过程
- 序列化和反序列化
- 数据压缩
- MapReduce InputFormat过程 OutputFormat过程
- MapReduce数据倾斜是什么?怎么判断是否存在数据倾斜?如何减缓数据倾斜?
资源调度系统YARN
- YARN是什么?
- YARN架构
- YARN运行原理
- YARN调度器
分布式相关原理
- 分布式的发展
- 分布式事务:2PC和3PC
- 分布式一致性算法:Paxos算法和ZAB协议
- 鸽巢原理
- Quorum NWR机制
- CAP理论
- BASE理论
分布式协调框架ZooKeeper
- 什么是ZooKeeper?为什么要用ZooKeeper?怎么用ZooKeeper?
- ZooKeeper命令行、java编程
- 基本概念和操作
- ZooKeeper工作原理
- HDFS HA方案
- ZooKeeper集群架构、读写流程
- leader选举、ZAB算法
- ZooKeeper状态同步
分布式数据仓库Hive
- hive是什么?
- 数据库和数据仓库的区别
- 架构原理
- 交互式方式
- 数据类型和DDL语法操作
- 数据导入方式和数据导出方式
- 创建分区表和使用方式
- 静态分区和动态分区
- 分桶表作用
- select查询语句
- hive表的数据压缩和文件存储格式
- hive的自定义UDF函数
- hive如何优化
- 如何避免或减轻数据倾斜
分布式列式数据库HBase
- HBase是什么?怎么用?
- HBase shell 命令基本操作
- HBase整体架构
- HBase表的数据模型
- HBase的数据存储原理
- HBase读、写数据流程
- HBase的flush、compact机制
- region 拆分机制
- HBase表的预分区
- region 合并
- HBase与Hive的对比
- HBase协处理器
- HBase表的rowkey设计、热点
- HBase的数据备份、二级索引
分布式消息系统Kafka
- 为什么有消息系统
- Kafka核心概念、集群架构、集群启动和停止、命令行的使用、生产者和消费者api代码开发
- kafka分区策略、文件存储机制
- 为什么Kafka速度那么快
- Kafka的内核原理之ISR-HW-LEO机制
- producer消息发送原理 、consumer消费原理、consumer消费者Rebalance策略
- kafka监控工具安装和使用
日志采集框架Flume
- Flume是什么
- Flume的架构
- Flume采集系统结构
同步MySQL增量数据工具Canal
- mysql主备复制
- mysql二进制文件格式
- Canal概念、工作原理、架构设计
数据迁移工具Sqoop
- sqoop的核心概念
- sqoop的架构原理
- sqoop的导入、导出
工作流调度器Azkaban
- 为什么需要工作流调度系统
- Azkaban的核心概念
- Azkaban的架构原理
- Azkaban的安装和使用
内存计算框架Spark
- spark是什么?有什么用?怎么用?
- spark-shell的使用、通过IDEA开发spark程序
- spark的RDD是什么?有什么用?它的五大属性是什么?怎么创建?算子分类?常见的算子操作有哪些?
- RDD的依赖关系、lineage(血统)、RDD的缓存机制、RDD的checkpoint机制、DAG有向无环图的生成、DAG如何划分stage
- spark运行架构、任务的提交、共享变量、application、job、stage、task之间的关系
- spark on yarn原理和机制、collect 算子操作剖析
- 任务中资源参数剖析、任务的调度模式、任务的分配资源策略、shuffle原理分析
- sparksql是什么?有什么用?DataFrame是什么?常用操作有哪些?DataSet是什么?
- Spark应用程序性能优化、基于Spark内存模型调优、数据倾斜原理和现象分析
- sparkStreaming实时模块
实时计算框架Flink
- Flink基本原理:是什么?怎么用?
- Flink常用数据源
- 常见Transform操作、常见sink操作、DataSet算子操作
- Flink架构以及任务如何提交到集群
- Flink的State知识、三种State Backend
- Flink checkpoint和savepoint原理以及重启策略
- Flink的waterMark的机制
- Flink window的类型和常用方法
老刘秋招大致就记了这么多东西,如有遗漏,请多多批评指正!
总结
看到大数据组件这么多,可能会有人问这么多东西看得完吗?说实话东西确实多,但是大数据开发组件就是前期可能困难点,因为很多东西没有接触过,老刘前期学习过程中非常痛苦,但把HDFS、MapReduce、YARN学习完之后,像打通任督二脉一样,后面内容学得越来越顺利。同时在学习过程中,要多看看牛客大数据开发面经,看看有没有哪些知识点忽略了,查漏补缺是必须的!
老刘是研二开始学这些东西的,当时都没有这些学习路线,全是老刘在网上各种找,各种总结,最后才知道应该如何学习大数据开发。因为要学的东西特别多,老刘于是每天早上早起一点,多背一点知识点,晚上迟点睡,把知识点巩固一遍,日积月累终于从量变到质变。就像我持续关注的大佬阿秀说的慢慢学、慢慢看,慢慢的就会有收获了。
笨鸟先飞,勤能补拙,从小就被教育这些东西是有用的,特别是对于老刘这种非科班双非无实习无项目的平常人。
最后,送给大家一句话,挺住就意味着一切,加油各位!

0 留言